Automate
Advanced Automation of SAP Failed Job Restart
IT-Conductor can automate the whole process of job abort detection, restarting SAP failed jobs, and notifying the job owner with job log as an...
Effectively managing and monitoring clusters demands advanced features to match the evolving complexity and scale of modern environments.
Cluster monitoring involves managing a network of interconnected components, referred to as a cluster, within a designated environment. Clusters, often consisting of interconnected servers, databases, or computing nodes, are the backbone of numerous applications, ranging from web services to enterprise solutions. As organizations adopt hybrid cloud environments, microservices architectures, and containerized workloads, the traditional methods of monitoring may face limitations in keeping pace with the evolving complexity and scale of modern cluster environments.
Furthermore, with the proliferation of various advancements in technologies and deployment models, such as serverless computing and edge computing, the scope and diversity of cluster environments continue to expand. This expansion introduces new challenges for monitoring, including ensuring consistent visibility and control across distributed and decentralized architectures. Hence, effective monitoring of cluster environments demands innovative solutions that can adapt to landscapes becoming more complex over time.
IT-Conductor provides native database cluster support through its existing SAP Host Agent monitoring infrastructure. The clustering support feature includes failover and scale-out capabilities, which enhances the ability of end-users to manage systems seamlessly within IT-Conductor.
Failover: Establishing primary and secondary (cold or hot) systems for enhanced availability and disaster recovery.
Scale-out: Implementing multiple members, normally of equal affinity, to enhance performance and resilience.
Cluster monitoring in IT-Conductor extends beyond direct monitoring, providing insights into cluster health, performance metrics, and replication lag. Leveraging the cluster controller functionality, users can determine the status, state, and current role of the database system accurately.
The cluster service also promptly detects and alerts you when a switch occurs from the primary to the secondary and vice versa.
IT-Conductor cluster monitoring applies to databases such as HANA and ASE, enabling the monitoring of each system node to detect failovers, with the capability to support multiple occurrences.
Selection of members for inclusion in the cluster is restricted to the Site or Role associated with the system, such as Production, QA, or Development. For instance, if the cluster is configured exclusively for Production, only Production-related instances are eligible for inclusion.
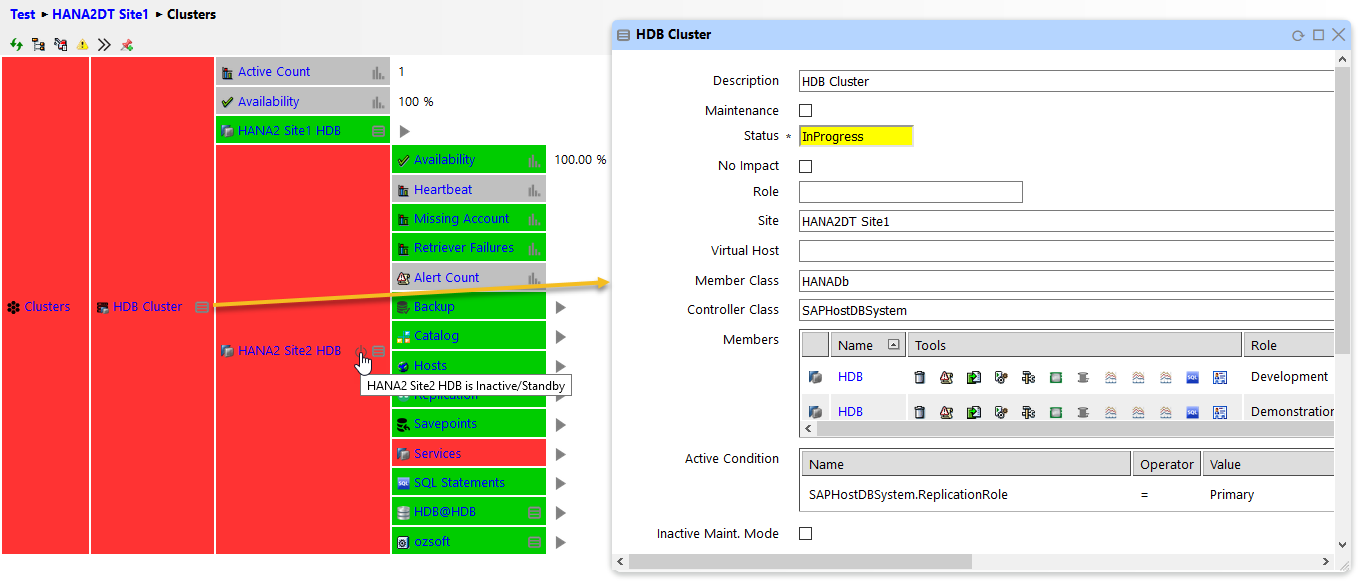
Figure 1: HANA Cluster Monitoring in IT-Conductor
The cluster service automatically discovers active and inactive systems. Inactive systems can be set to Maintenance Mode and reactivated without the need for manual intervention.
The cluster service boasts additional features, such as the Active count, which indicates the precise number of active systems. Furthermore, it includes an Availability feature that showcases the average availability of all active instances in a scale-out cluster scenario.
Primarily implemented for monitoring HANA and ASE database clusters, this capability is compatible with other databases as well.

Figure 2: ASE Database Cluster Monitoring in IT-Conductor
By monitoring the key aspects of a database cluster, organizations can proactively identify and address issues, optimize performance, and ensure the reliable operation of their database infrastructure.
See HA/DR Monitoring Documentation for more details.
As organizations strive to maintain the integrity and performance of their cluster environments, the integration of advanced monitoring features has become indispensable. In the face of exponential data growth and increasing system complexities, relying solely on traditional monitoring methods proves inadequate for modern cluster management.
This section explores the advanced monitoring features of IT-Conductor designed to complement cluster monitoring.
Automated Recovery Actions play a crucial role in cluster monitoring by providing proactive measures to address potential issues detected within the cluster environment. When anomalies or performance degradation are identified through monitoring, Automated Recovery Actions can automatically trigger predefined remediation steps to restore the cluster to a healthy state.
For instance, if a database node within the cluster experiences a sudden spike in resource utilization or becomes unresponsive, Automated Recovery Actions can initiate processes such as restarting the node, reallocating resources, or failing over to a standby node. By automating these recovery actions, organizations can minimize downtime, mitigate the impact on system performance, and ensure the continuous availability of critical services.
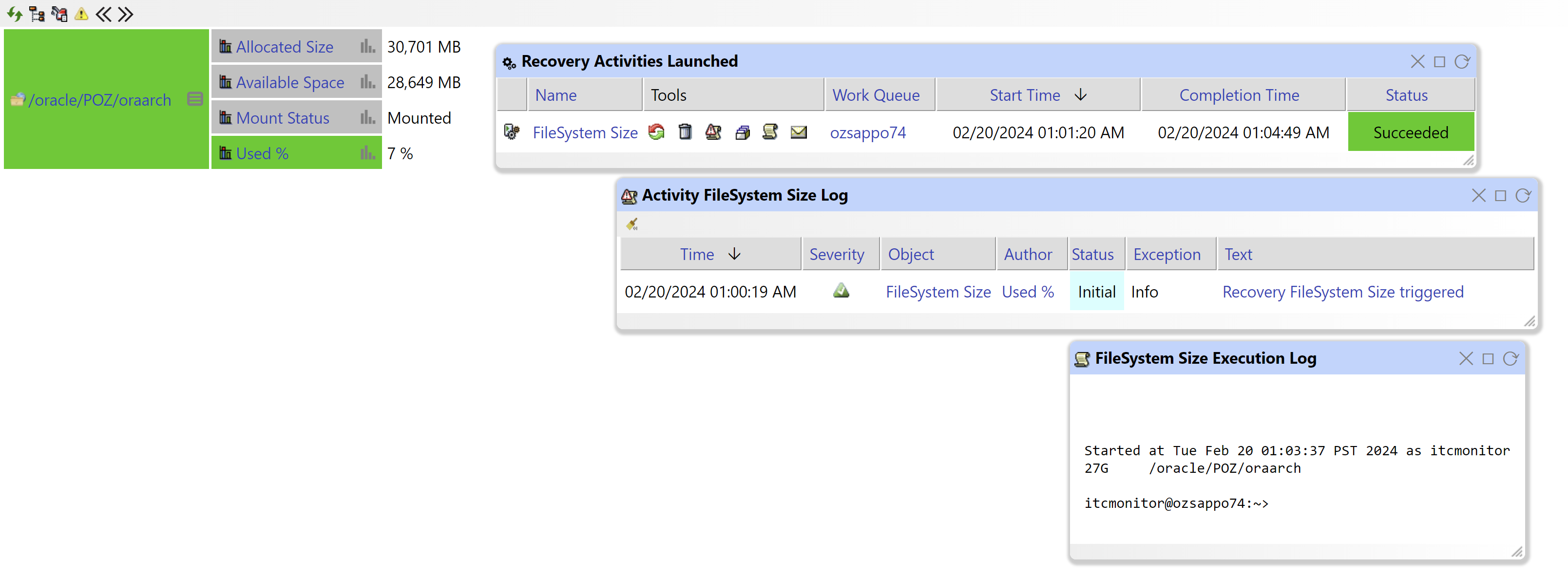
Figure 3: Filesystem Size Auto-Remediation
Implementing end-to-end transaction monitoring within a cluster environment enables organizations to track the entire lifecycle of transactions from initiation to completion, regardless of the number of nodes or servers involved. This allows for the identification of performance bottlenecks, latency issues, or failures that may occur at any point within the transaction flow.
For instance, if a transaction fails to complete successfully due to a database error or server outage, this monitoring capability can provide visibility into the root cause, enabling swift resolution and minimizing the impact on overall system performance.
Furthermore, by monitoring user interactions across distributed systems, organizations can pinpoint performance bottlenecks and enhance the overall end-user experience.
 Figure 4: End-User Transaction Monitoring
Figure 4: End-User Transaction Monitoring
Security monitoring within a cluster environment involves continuously monitoring network traffic, system logs, and user activities to detect suspicious behavior, unauthorized access attempts, or potential security breaches. By analyzing security logs and audit trails from all nodes within the cluster, organizations can identify indicators of compromise and take immediate action to mitigate security risks.
For instance, security monitoring may detect unusual login attempts or unauthorized access to sensitive data within the cluster. In such cases, security alerts can be triggered to notify administrators, who can then investigate the incident and implement appropriate remediation measures, such as blocking the malicious user or isolating compromised nodes from the network.
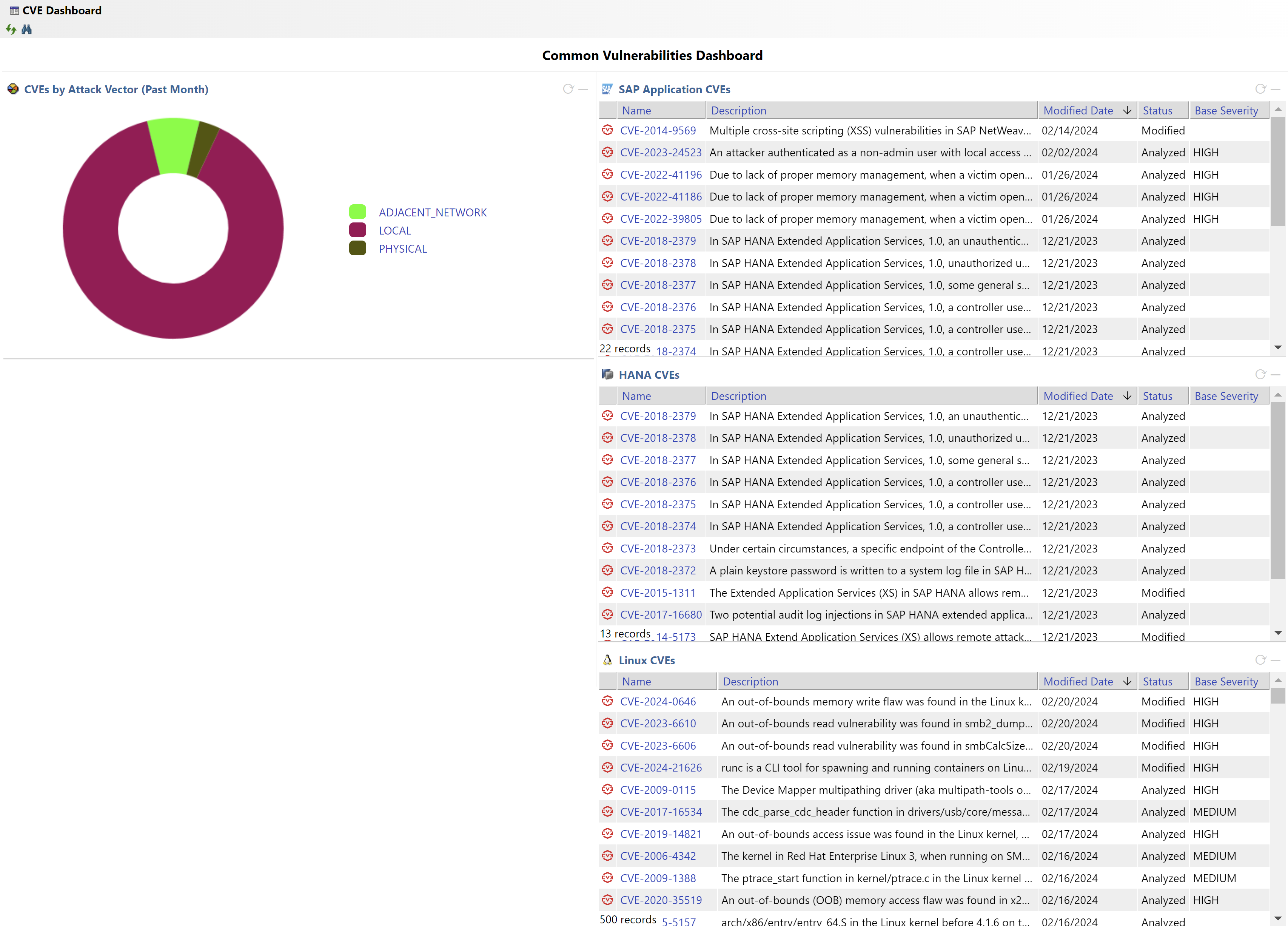 Figure 5: IT-Conductor CVE Dashboard
Figure 5: IT-Conductor CVE Dashboard
In a clustered environment, where multiple nodes or servers interact to support various applications and services, maintaining consistency in configuration and deployment is important to maintain reliable operation.
IaC Monitoring enables organizations to track changes and configurations made to cluster components, ensuring alignment with organizational standards and best practices. By monitoring changes in infrastructure code and deployment scripts, organizations can detect deviations from desired configurations, potential security vulnerabilities, or compliance issues within the cluster environment.
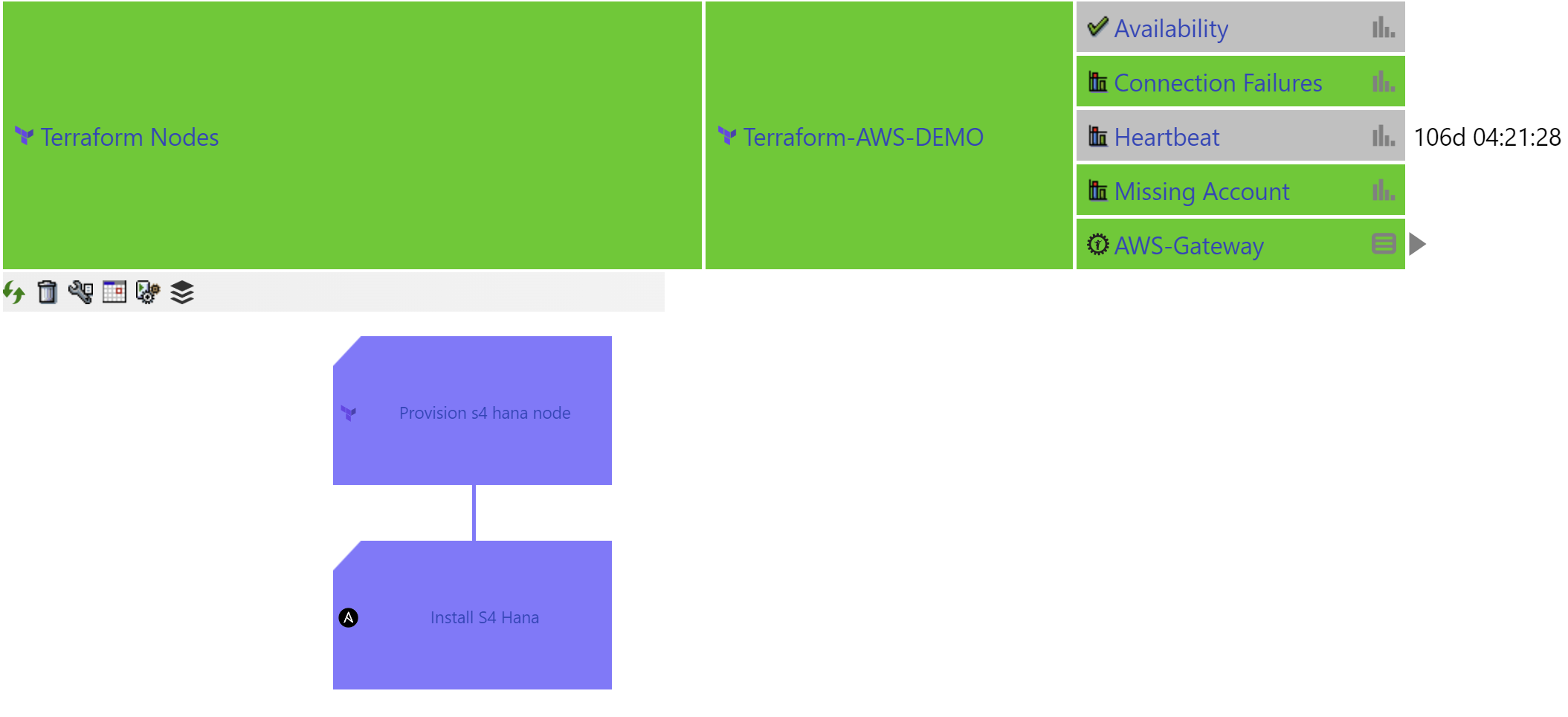 Figure 6: IT-Conductor Integration with Terraform
Figure 6: IT-Conductor Integration with Terraform
Integration with DevOps pipelines enhances cluster monitoring by embedding monitoring processes and feedback loops within the development and deployment workflows.
By incorporating monitoring processes within DevOps pipelines, organizations can continuously assess the health, performance, and security of their clustered environments throughout the development and deployment phases. This means that monitoring is not treated as an afterthought or a separate activity but rather as an integral aspect of the entire software delivery process.
For instance, as developers commit code changes and trigger automated builds in the DevOps pipeline, integrated monitoring processes can automatically perform tests to evaluate the impact of these changes on the cluster environment. This includes monitoring resource utilization, application performance, and system stability, among other key metrics. Any deviations or issues detected during this process can trigger immediate alerts or notifications to the relevant teams, enabling quick resolution before the changes are deployed into production.
Moreover, by incorporating feedback loops into DevOps pipelines, organizations can continuously gather insights from monitoring data and use them to drive iterative improvements. This means that as applications are deployed and run in the clustered environment, data collected from monitoring processes can inform future development decisions, helping teams optimize performance, scalability, and resource allocation over time.
 Figure 7: IT-Conductor Integration with DevOps Tools
Figure 7: IT-Conductor Integration with DevOps Tools
By integrating these advanced monitoring capabilities into cluster environments, organizations can effectively manage the complexities of modern cluster environments and ensure the continuous delivery of high-performance, resilient, and scalable applications across diverse industries and use cases.

IT-Conductor can automate the whole process of job abort detection, restarting SAP failed jobs, and notifying the job owner with job log as an...
Monitor the components of your SAP Fiori system landscape, especially the SAP Gateway, to ensure that SAP Fiori applications are running without...
Q3-2021, Scheduled Event, RCA of SAP Job Cancellation, Subscribers Report, Online HTML Reports, Cloud-Native SID-Refresh, FIORI Gateway, SAP LMDB...