With contributions from Femi Charles and Linh Nguyen
It is quite normal to encounter failed jobs in SAP and there can be several reasons as to why they fail or get canceled. There are no statistics that show what are the common reasons behind these failures but we can be sure that some of them are attributed to issues regarding user authentication and authorization, file-sharing permissions, incorrectly defined variants, resource constraints, data quality, and so on. In large SAP environments, there can be thousands of jobs per day, and the associated job monitoring and task management can be very burdensome for these organization’s IT operations teams.
While some failed jobs can be ignored, those jobs that are critical require rigorous monitoring and most organizations already know this. This is why monitoring tools are in place to oversee the performance of the whole SAP environment including the status of the jobs running in the background. However, there are still instances where failed critical jobs are overlooked and when that happens, the business is already on the brink of extensive monetary loss.
Table of Contents
How SAP Administrators Address Failed Jobs
How to Automate Failed Job Restart in IT-Conductor
1. Creation of a Dedicated SAP Service User for Job Restart Operations
2. Required Authorization
3. Creation of Job Restart User Accounts in IT-Conductor
4. Creation of Threshold Overrides
5. Definition of Recovery Activities
Minimizing Risks When Automation Fails to Restart a Job
Automation with IT-Conductor: Back to Basics
When it is apparent that a critical job has been aborted, either through monitoring or the job owner reporting an incident, there may be a significant delay in checking operation processes on what to do with the failed job aka job recovery. In most common cases, the job can simply be rerun. While in more complex cases, it should only be rerun from the failed step. Again, this determination and manual action can extend the MTTR (Mean Time to Repair) and potential business loss due to the impact on dependent business operations.
Remember that infamous case of Hershey’s ERP implementation failure where the company failed to process around $100 million worth of Kisses and Jolly Rancher candies for Halloween? That certainly resulted in an 8% dip in Hershey’s stock price and a 19% drop in their quarterly profits back in the year 1999. An almost similar case occurred with Nike that caused them to lose sales of around $100 million and a 20% decline in stock price. While some of these cases were attributed to implementation delays, configuration issues, and complex integration problems, others can be attributed to operation process deficiencies.
This is the very reason why it’s important for organizations to properly plan out ERP implementation and consider all possible risks (business and technical), so that when incidents happen, subject matter experts can quickly address the issue at hand and mitigate their impact on the business.
How SAP Administrators Address Failed Jobs
Given the importance of addressing failed jobs, especially the critical ones (you know the ones that have money tied to them), SAP administrators have gone through different techniques to resolve failed and/or canceled jobs. Regardless of what application or module the issue occurred in, administrators should know how to debug and revert the system to its previous state, reverse engineer the error to find out what went wrong and resolve the issue before running the job again.
Some jobs require running with a specific variant from a particular step or from the beginning of the job which involves a slow, tedious, and unreliable process considering the fact that restarting SAP jobs are performed manually. Moreover, ensuring critical jobs run successfully at a set time is as important especially if the jobs are required to run outside business hours.
What if we tell you that restarting failed jobs in SAP can be automated?
How to Automate Failed Job Restart in IT-Conductor
IT-Conductor can automate the whole process of job abort detection, restarting SAP failed jobs, and notifying the appropriate job owner, including the job log as an attachment. In advanced cases, IT-Conductor can even restart the job with a specific variant, and/or from a specific step. Depending on the complexity of the conditions on how you want to restart a particular job, IT-Conductor can be configured to execute this tedious process, to reduce the MTTR. Consequently, the reliability of the process being executed will increase, eliminating the risks that come with aborted jobs going unnoticed.
The automation of failed job restart in IT-Conductor requires the following to properly execute this operation. We are providing the steps to show you how easy it is to configure, however, IT-Conductor is a full-service SaaS solution so we can configure everything below for you except Step 2.
1. Creation of a Dedicated SAP Service User for Job Restart Operations
Service users in SAP are used to perform internal operations. It does not require a password.
The service user must be defined in SAP to execute the job restart operation that will be triggered later on as the operation progresses.
2. Required Authorization
The created service user should be assigned the required authorization to execute the job restart operation on the customer’s end. This is performed by importing the security role provided by IT-Conductor into the customer’s system using the PFCG transaction code and then assigning the role to the created service user.

Figure 1: IT-Conductor SAP Security Download Files
3. Creation of Job Restart User Accounts in IT-Conductor
In IT-Conductor, the creation of a user account that reflects the same SAP user created on the customer’s end is required. This will be used to trigger the job restart from IT-Conductor. It is also important that the user account to be created in IT-Conductor must have a jobadmin role to successfully trigger the job restart whenever the defined conditions in the job match the defined threshold override.

Figure 2: Application Accounts in IT-Conductor
4. Creation of Threshold Overrides
Given the notion that failed jobs must match the criteria defined in the threshold override before a job restart operation is initiated, the creation of threshold overrides then must be properly defined. This is due to the fact that it is used to detect and trigger the job restart operation. Thus, not specifying the appropriate conditions will not trigger the job to run again.
Threshold overrides are defined per monitored metric in a system. Depending on what jobs you want to automatically restart as it fails, you have to carefully consider the process or the different steps associated with it because in some cases, jobs need to run in a specific sequence.

Figure 3: Aborted Overrides in IT-Conductor
5. Definition of Recovery Activities
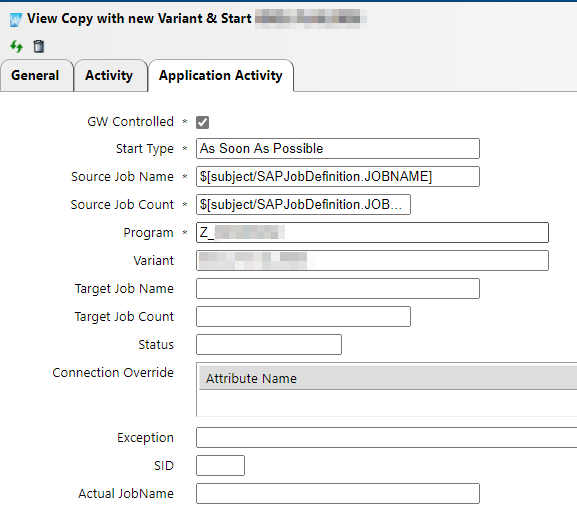
Automatic job restart operation is simply copying and starting a job to run again when it fails. However, for more complex processes, the use of variants is necessary.
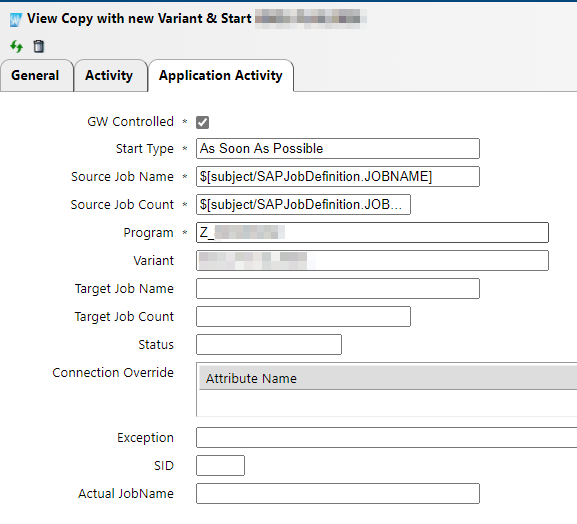
Figure 4: Application Activity Details of in IT-Conductor
Let’s say, for example, you need to regularly run a job to create a monthly report that uses the same fields but with a varying range of values each time the job runs. In order for automatic job restart operation to initiate, you need to create a variant where you can save the selection parameters needed to successfully run the monthly report. Doing so allows you to eliminate the need to manually enter the range of values each time the job fails to execute.
This goes to show that defining the recovery activities is as important as creating the threshold overrides because a single error could cause the job restart operation to fail which could then result in erroneous reports, inventory inaccuracies, or even greater damage such as misrepresented financial data that can cause the business significant loss in revenue.
Minimizing Risks When Automation Fails to Restart a Job
When implementing automated solutions, such as the automatic job restart operations described in this article, it is highly advisable that careful planning and a series of rigorous tests are performed to assess the reliability of the process being executed.
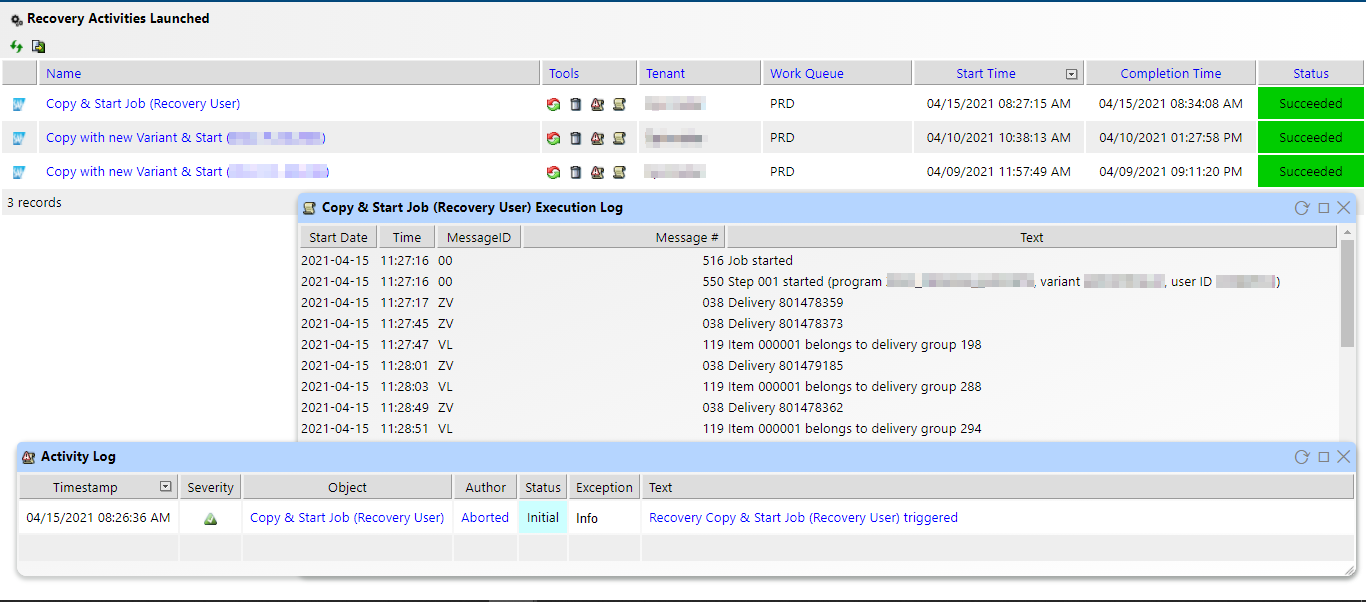
The execution log in IT-Conductor will show you details on a more granular level such as what step (if the job involves multiple steps) the job failed to execute. If you want to investigate and check what specific error occurred while restarting the job, you can navigate to the application log and start your troubleshooting from there.
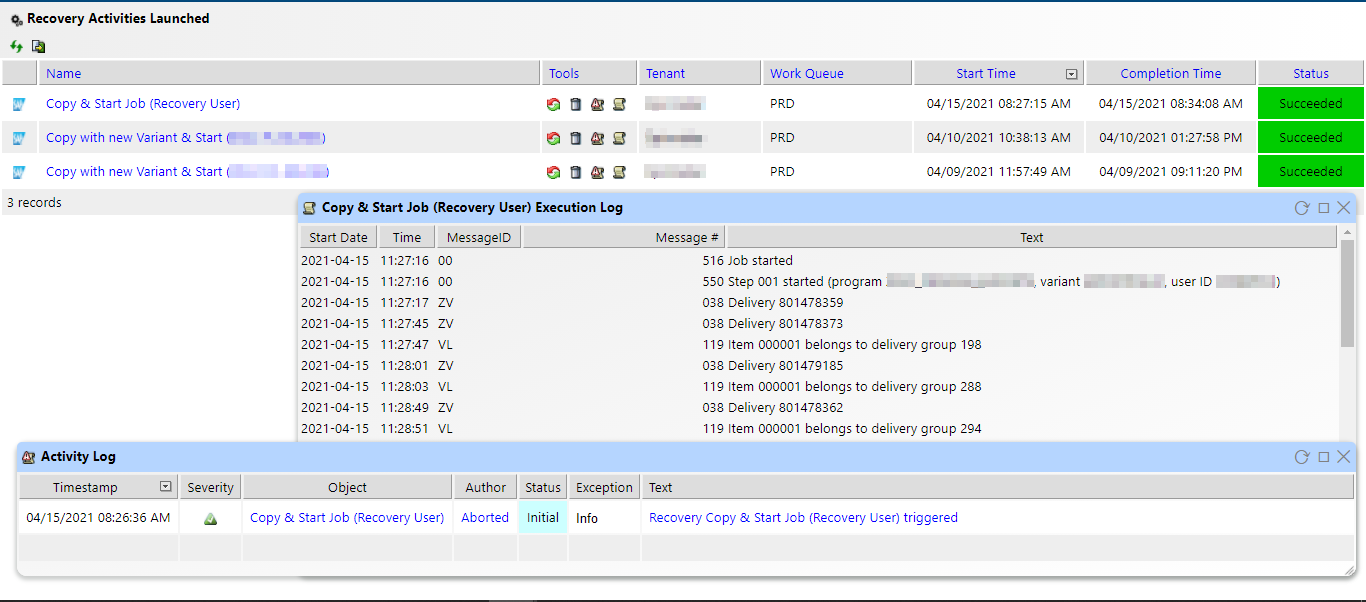
Figure 5: Recovery Activities and Logs in IT-Conductor
Alerts can also be configured to be sent for each job failure and recovery you subscribed to. This is extremely helpful if you want to further increase your monitoring efforts and minimize the risks should automation fail to restart the jobs. Other advanced features of job recovery include the ability to restart only once, so in case manual intervention is needed due to repeated failures, IT-Conductor does not keep restarting the same job. It is especially useful when the job abort is due to a data quality issue that must first be remediated by an analyst.
Automation with IT-Conductor: Back to Basics
Every time you think about what else is there to automate in your day-to-day operations, it is fair to say that you always start thinking about the complex ones. Little did you know that automating simple tasks such as restarting jobs can save your organization from experiencing major losses, not only in revenue but also in the trust of your customers. Furthermore, organizations do not need to invest in large operations teams, monitoring analysts, and tools experts, when all the automation can be set up per customer’s requirements and maintained by IT-Conductor inclusive monitoring as a service solution. This means customers can focus more on their critical IT projects.
If you want to learn more, our team of industry experts is more than willing to show you the endless possibilities that IT-Conductor can do to automate operations in your environment.
Your SAP environment can be fully monitored and managed in minutes.