Taking a proactive approach to server management is more than just keeping systems up and running—it’s about creating a secure, reliable environment that supports your team and earns customer trust. By following proven best practices, organizations can prevent unexpected disruptions, enhance performance, and protect valuable data. Without strong server management practices, organizations face risks like downtime, slow performance, and potential security breaches. These challenges can disrupt team productivity, lead to financial setbacks, and damage a brand’s reputation, ultimately impacting customer trust and business growth. Proactive server management, however, provides a solid foundation for a resilient IT infrastructure, helping to keep operations running smoothly and setting the stage for long-term success.
In this blog post, we will explore the fundamental components of server management, from understanding its core concepts to implementing best practices in maintenance, optimization, and disaster recovery.
Server management involves all activities and tasks to keep servers running smoothly, securely, and efficiently. This includes managing the hardware and software aspects of servers, ensuring they perform well and experience minimal downtime. Since servers host applications, websites, and data, they are critical in keeping business operations up and running.
Server management activities include configuring the server environment, installing software, regularly applying patches and updates, monitoring performance, and implementing security measures. The ultimate goal is to build a stable, efficient, and secure infrastructure that supports the organization’s needs and meets service level agreements (SLAs) to deliver reliable service.
Key metrics to track for proactive server management
Monitoring specific server metrics helps system administrators proactively identify and address issues.
Here are the key metrics to include in your monitoring strategy:
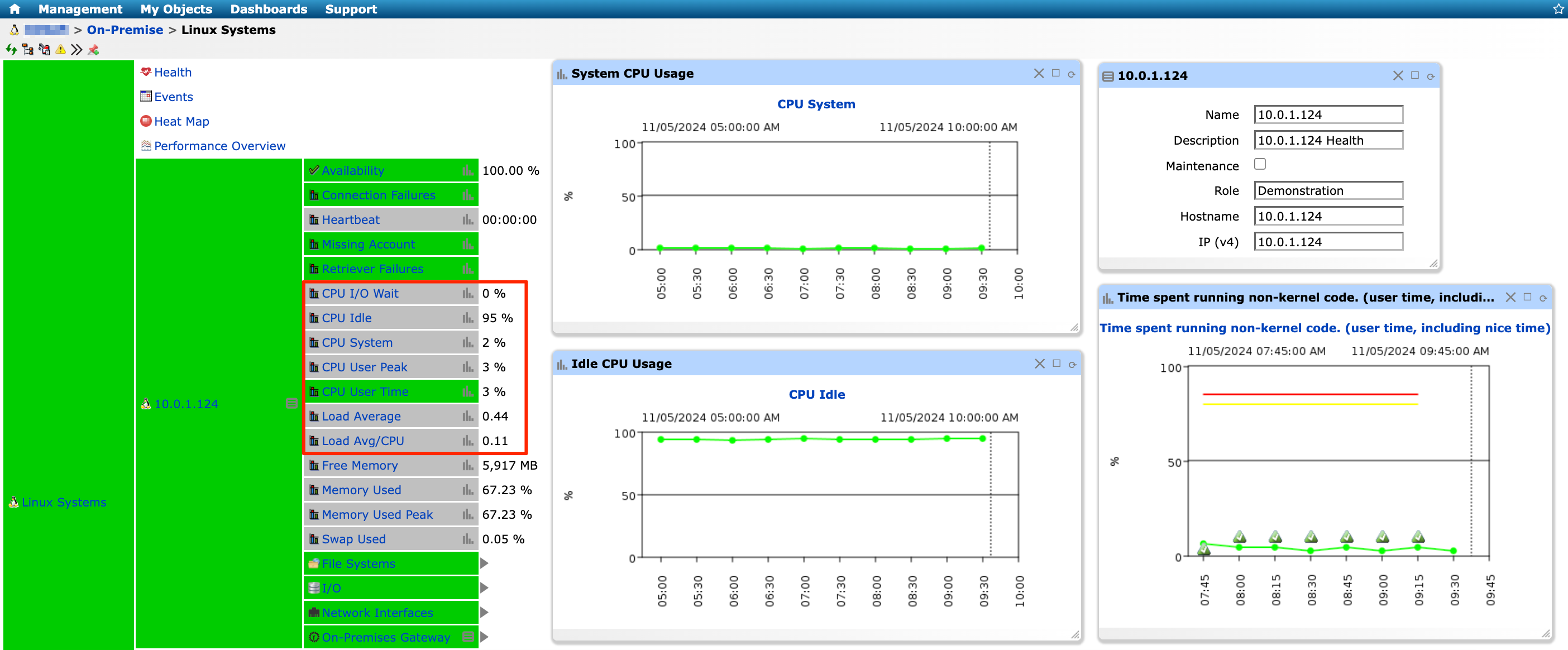
1. CPU usage
Monitoring CPU load helps to prevent performance bottlenecks that can slow down your applications. When the CPU is consistently under heavy load, it may indicate that the server is struggling to keep up with the application workload. Over time, high CPU usage can lead to sluggish response times and a frustrating experience for users.
Figure 1: Server CPU Usage Monitoring in IT-Conductor
Best practice: If CPU usage remains high, consider upgrading your server or reallocating resources to distribute the workload better. This could mean adding more powerful hardware or optimizing how resources are assigned to different tasks.
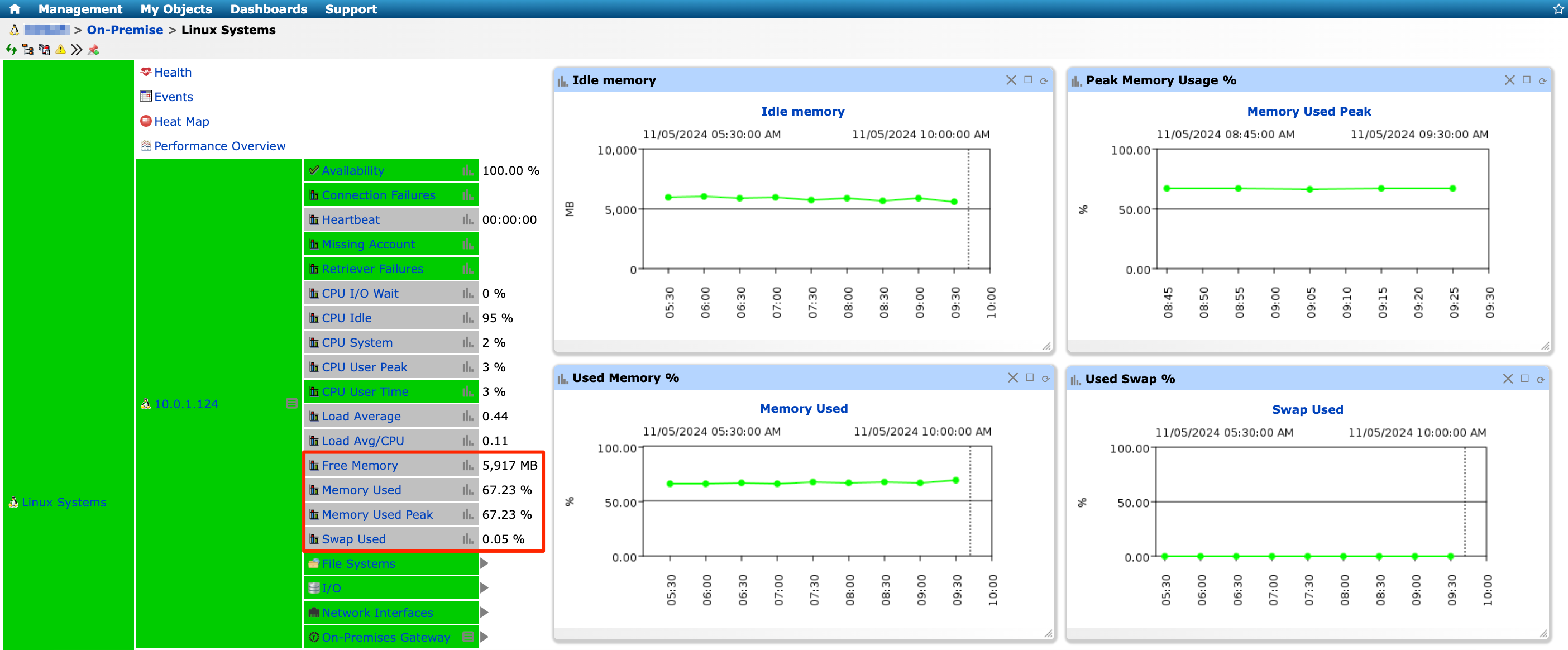
2. Memory usage
Recent enterprise computing trends have increased memory demands for faster response times, particularly with in-memory databases such as SAP HANA, and caching on application servers to reduce database and/or IO access. Thus, RAM usage is an important indicator of overall server health and performance. When your server has sufficient RAM, it can store more data and provide quick access to query data, ensuring that applications respond promptly and users have a seamless experience.
However, when memory resources are insufficient, you might notice issues like application crashes or frustratingly slow response times. This can be especially problematic during peak usage periods when many users access the system simultaneously. High RAM usage can strain your server, causing it to slow down or freeze, disrupting operations and leading to poor user experience.
Figure 2: Server Memory Usage Monitoring in IT-Conductor
Best practice: Identify servers running low on memory during peak times. Reallocate resources to balance the load better. If memory usage remains high, consider upgrading server RAMs.
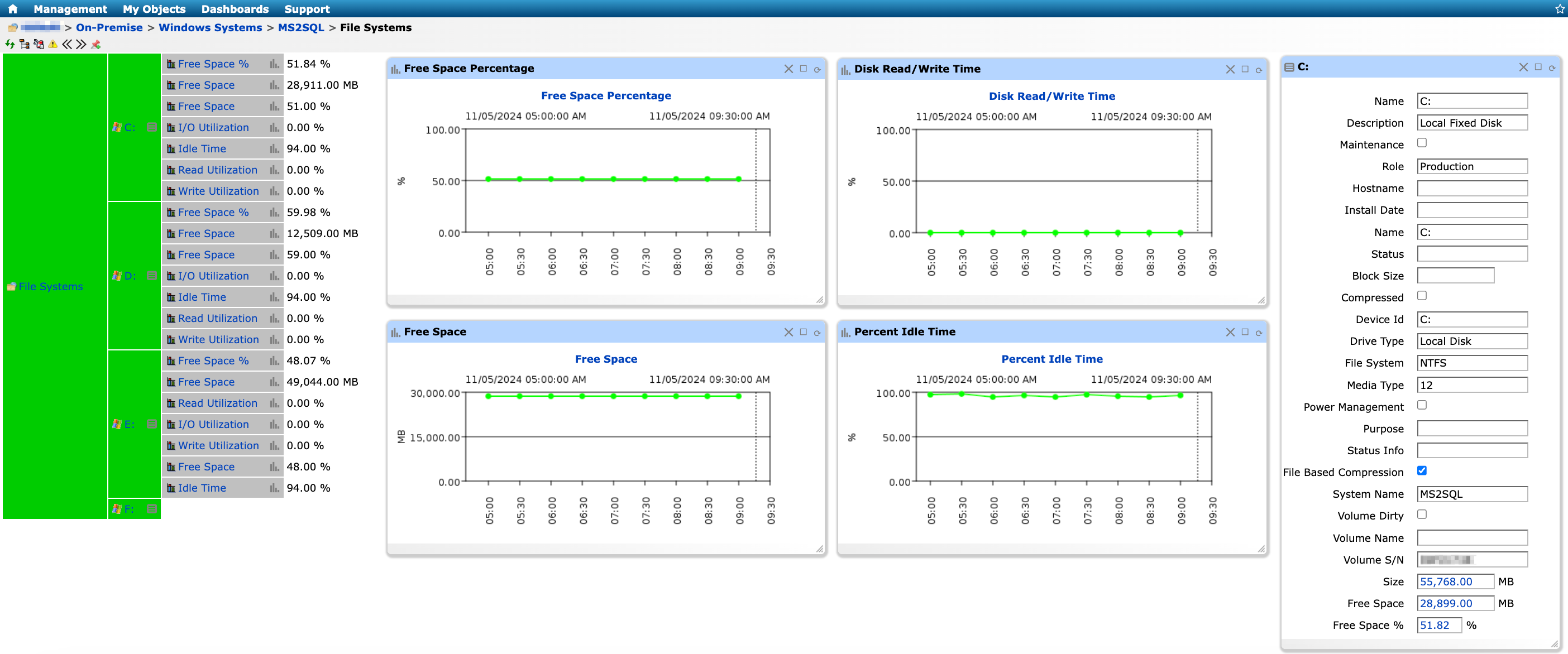
3. Disk usage and I/O utilization
Understanding how disk space is used and monitoring I/O utilization ensures the server has adequate space and speed to handle data read/write (RW) processes.
Disk space is like a filing cabinet for your server—if it’s too full, it can’t store new files or data, which can lead to errors and crashes. Monitoring disk space helps you know when you’re running low and need to clean up unnecessary files or expand your storage capacity.
I/O utilization refers to how quickly your server can read and write data to and from the disk. If the I/O utilization is high, it can create bottlenecks that impact applications relying on quick access to data. This can lead to frustrating delays for users, particularly when they’re trying to retrieve or save important information.
Figure 3: Server Disk Usage & I/O Utilization Monitoring in IT-Conductor
Best practice: Regularly check disk usage and I/O utilization. Configure threshold overrides to send notifications whenever server disk usage approaches critical levels. Free up space by deleting unnecessary files or expanding storage capacity.
You may also consider implementing a solution that tracks disk activity continuously and performs disk cleanup automatically. See OS File System Cleanup Automation.
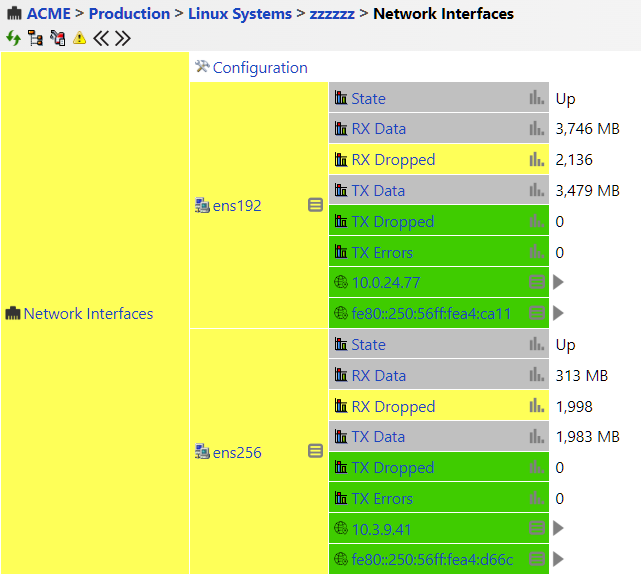
4. Network interface traffic and response time
Monitoring inbound and outbound network traffic is like keeping an eye on the flow of cars on a busy highway. Just as traffic patterns can reveal road congestion or accidents, tracking network traffic can highlight areas where your server might be slowing down or under attack.
When you monitor traffic closely, you can quickly spot if your bandwidth—the maximum amount of data your server can handle at a time—is being stretched thin. This might happen during peak usage times or if too many applications simultaneously demand resources. Bandwidth limitations can lead to slower performance for users, resulting in delayed responses and frustration, especially if they’re trying to access important applications or data.
Figure 4: Linux Network Interface Monitoring
Traffic monitoring also acts as an early warning system for security threats. For instance, if you notice a sudden spike in incoming traffic from unusual sources, it could signify a Distributed Denial of Service (DDoS) attack, where attackers flood your network to disrupt services. Outbound traffic spikes might signal data breaches, indicating that unauthorized users are trying to extract sensitive information.
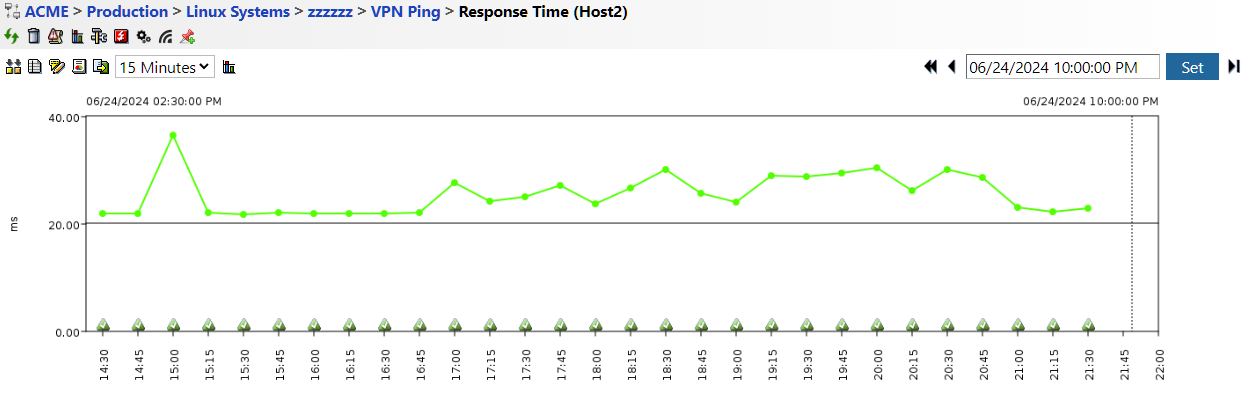
Figure 5: Server Response Times Monitoring in IT-Conductor
Best practice: Network monitoring is a specialized area on its own. In the context of server management, monitoring the server’s network interface helps you catch networking issues without needing deep knowledge of routing and switching.
If you see high bandwidth usage or spot issues in the network interface status on the server—such as errors, throughput drops, or unusual remote host ping statistics—you can take proactive steps to allocate additional resources on the server’s end. See Linux Network Interface Monitoring for more details.
Consistent delays in response times in server logs also indicate overloaded resources or potential network bottlenecks. When these delays appear, investigate resource usage and network traffic to identify areas needing additional capacity or optimization.
For server-focused environments, opt for lightweight monitoring solutions that provide insights without the complexity of a full-scale network monitoring setup. This is especially beneficial in cloud environments, where the provider often manages network infrastructure, and you may only need visibility into specific server-level metrics. Lightweight solutions allow you to focus on tracking key indicators like bandwidth, latency, and interface health without getting bogged down in intricate network configurations.
5. Error logs
Regularly analyzing server logs for patterns—like repeated errors—can uncover deeper issues affecting your applications or infrastructure. These logs are like a record of your server's day-to-day health, capturing details of system activities, error messages, and performance metrics. By examining them closely, you can spot recurring problems that might go unnoticed, such as a specific application frequently timing out or a component consistently underperforming.
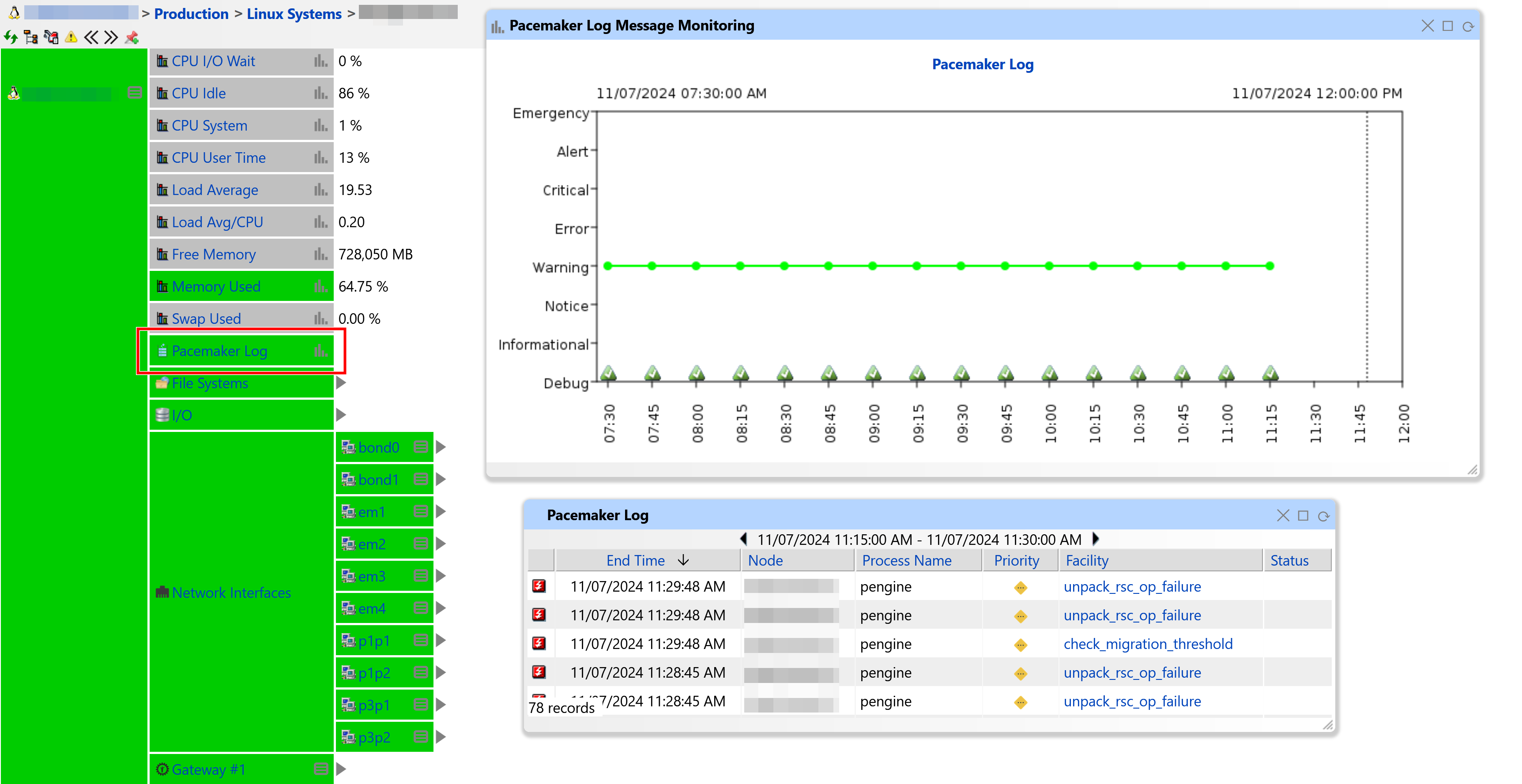
Figure 6: Pacemaker Log Monitoring in IT-Conductor
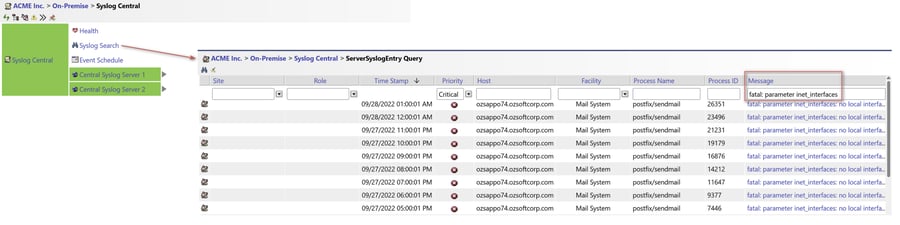
Implementing Central Syslog Server Monitoring through a centralized Syslog server, such as one configured to run on the IT-Conductor Gateway, enhances these efforts by breaking down silos and enabling enterprise-wide insights. Centralized storage allows administrators to search through Syslogs and set up notifications for events that meet defined criteria, making it easier to detect and respond to issues as they arise.
Figure 7: Central Syslog Server Monitoring in IT-Conductor
Best practice: If an application consistently generates the same error, take time to investigate the root cause. Repeated errors may indicate a configuration issue, compatibility problem, or the need for a software update.
6. Uptime and downtime
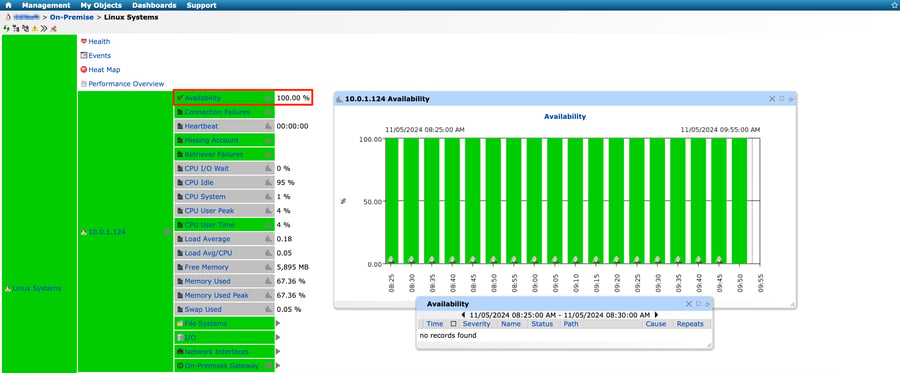
Uptime refers to the total duration your server is operational and accessible to users, while downtime indicates periods when the server is unavailable due to maintenance, failures, or unexpected issues. Monitoring them both is crucial for determining the availability and evaluating the reliability of your servers. High reliability ensures that users can access applications and services as expected. Conversely, frequent downtime can lead to frustration, lost productivity, and potential revenue losses, highlighting the importance of maintaining a stable server environment.
Figure 8: Server Availability Monitoring in IT-Conductor
Best practice: Implement redundancy and failover systems to minimize downtime during maintenance or unexpected issues. This ensures that if one server goes down, another can take over seamlessly, maintaining availability for users. Also, regularly test your disaster recovery and backup plans to ensure they are effective and can be executed quickly in the event of a server failure.
Plan and communicate maintenance windows. If possible, schedule patching or upgrade activities during off-peak hours. This minimizes user impact and helps ensure that necessary updates and checks are performed without causing significant downtime.
Server maintenance and regular updates
Server maintenance and regular server updates or patching are crucial for keeping servers secure and efficient.
Here are the most common activities performed by server administrators on a regular basis:
Operating system and software updates: Software updates encompass a broader range of improvements, including bug fixes, performance enhancements, and new features. They may be released periodically, often on a schedule determined by the software vendor, such as quarterly or semi-annually, and can include multiple enhancements. While software updates may include important security fixes, they also aim to enhance performance and usability.
To update SAP kernels, we have developed a SAP Kernel Update Automation solution that simplifies the process and makes the SAP Basis administrator’s life significantly easier.
Security patches: Security patches are specifically designed to address vulnerabilities and weaknesses in software that malicious actors could exploit. These patches are often released as needed, mainly when a new vulnerability is discovered. Some vendors may also have regular schedules for releasing security patches. For instance, SAP observes a designated SAP Security Patch Day on the second Tuesday of every month, aligning this schedule with the security patch days of other major software vendors.
Backup management: Regular backups safeguard against data loss due to hardware failures, accidental deletions, cyberattacks, or other unforeseen events. Establishing a robust backup strategy helps ensure that critical data can be quickly restored during a disaster, minimizing downtime and maintaining business continuity.
We recommended setting up automated backups that run regularly to streamline this process. Automation reduces the risk of human error and ensures that backups are consistently performed without requiring manual intervention. To demonstrate how to automate backup operations in IT-Conductor, you can explore Age-based HANA Backup Automation. While this is one specific use case, IT-Conductor can manage various server backups, accommodating various data protection strategies tailored to your needs.
Log analysis: Regular log reviews are important in identifying unusual patterns that could signal security incidents or system malfunctions. Logs capture detailed records of all server activities and transactions, including user actions, system events, error messages, and network traffic. Systematically reviewing these logs allows you to determine issues before they become major incidents. Regular log reviews into your routine operational procedures enhance your overall security posture, creating a more resilient environment.
Hardware checks: Physical servers require hardware maintenance to ensure optimal performance and longevity, as components can wear out over time or be compromised by environmental factors. Servers generate significant amounts of heat during operation, and if not properly cooled, they can overheat, leading to hardware failures or reduced performance. Regularly checking the cooling systems—such as fans, vents, and air conditioning units—ensures they function correctly and maintain appropriate temperatures within the server environment.
Best practice: Establish a regular schedule for server maintenance and patching updates. Create a comprehensive maintenance plan that outlines specific dates and times and server hostname(s) with IP address(es). Ensure all steps are documented and develop a backup plan to address any potential failure during the activity.
By preparing for contingencies, you can minimize downtime and swiftly restore normal operations if any problems arise. This proactive approach enhances the stability and security of your servers and fosters a culture of preparedness and accountability within your IT team.
Optimizing server performance
Optimizing server performance is crucial for providing users with a seamless experience and maximizing server efficiency. When servers operate at their best, they can handle requests quickly and efficiently, translating to faster load times and smoother user interaction. This is particularly important for businesses that rely on online platforms, as slow or unresponsive servers can lead to frustration and lost opportunities.
Maximizing server efficiency is key to making the most of your IT resources. An optimized server reduces the strain on hardware, leading to lower energy consumption and reduced operational costs. This efficiency not only enhances performance but also extends the lifespan of your equipment, saving you money in the long run.
To achieve this optimization, consider implementing the following:
Load balancing: Use load balancing to distribute workload across multiple servers, preventing any single server from becoming overwhelmed. This strategy enhances overall server performance and improves reliability by ensuring that if one server experiences issues, others can seamlessly take over, maintaining continuous service availability for users.
Learn more about SAP Web Dispatcher Monitoring and how IT-Conductor can distribute incoming HTTP(S) requests from users or clients across multiple application servers in an SAP system landscape.
Caching: Implement memory-based caching mechanisms (e.g., Redis, Memcached) to reduce load times and server strain. By storing frequently accessed data in memory, you can significantly enhance the speed of data retrieval, allowing your servers to respond more quickly to user requests and ultimately improving the overall user experience.
Resource allocation: Regularly assess resource usage and allocate resources appropriately based on server demands. Consider scaling vertically (upgrading server resources) or horizontally (adding more servers).
Database optimization: Index frequently accessed tables and queries, regularly optimize the database, and minimize database calls where possible to reduce server load. This enhances the speed and efficiency of data retrieval and ensures your server can handle higher traffic volumes without compromising performance or response times.
Optimize application code: Inefficient code can be resource-intensive. Regular code reviews and optimizations improve response times and reduce server demands. Refining your codebase enhances application performance and contributes to a more efficient server environment, allowing for better resource utilization and a more scalable infrastructure.
By focusing on these areas, organizations can ensure servers deliver high-performance, consistent experiences even under heavy load. When servers are well-optimized, organizations can handle surges in activity without compromising speed or quality.
Disaster recovery and failover strategies
A disaster recovery (DR) plan is essential for minimizing downtime and ensuring business continuity when facing unforeseen incidents, such as natural disasters, hardware failures, or cyberattacks.
Here are some best practices for implementing DR and failover:
Data backups and redundancy: Having regular, automated backups stored in offsite or cloud locations means that you can quickly restore your data and get your systems back up and running if a disaster strikes. This approach ensures that important files and configurations aren’t lost due to unforeseen events like hardware failures, cyberattacks, or natural disasters.
Failover systems: Setting up failover systems, like clustering or using secondary servers, ensures that your services keep running smoothly even if the primary server goes down. This means that if something unexpected happens, your users won’t notice any disruptions, and you can avoid the frustration and potential losses that come with unexpected downtime.
Testing the DR plan: Regularly testing your DR plan helps ensure everything will work smoothly if needed. By running these tests, you can catch any issues early and adjust the plan to cover new risks, giving you confidence that your team is prepared for any situation.
Documenting procedures: Ensure your DR plan has clear, step-by-step instructions for recovering data so everyone knows exactly what to do if an incident occurs. This should include details like server configurations, contact information for key team members, and a timeline for getting everything back up and running. This documentation makes the recovery process smoother and less stressful for everyone involved.
Monitoring and alerts: Set up automated monitoring and alert systems so you’re instantly notified of any issues that could cause downtime. This way, your team can immediately respond to fix problems before they affect users, maintaining seamless operations and minimizing disruptions.
By having a comprehensive DR and failover strategy, organizations can quickly recover from unexpected events and minimize the impact on users and operations.
Empower your team with these server management best practices
Server management is an ongoing process beyond just fixing issues as they arise—it’s about anticipating needs and taking proactive steps to keep everything running smoothly. This means consistently monitoring your servers to catch any signs of trouble early, performing regular maintenance to keep systems healthy, and optimizing performance so your servers can handle demand without a hitch.
Tracking key metrics like CPU/Memory/Disk usage, I/O utilization, response times, uptimes, and downtimes, as well as monitoring network interface traffic and error logs, provides critical insights into server health and performance. Keeping everything up-to-date, from software patches to hardware upgrades, helps to close security gaps and keeps your systems running at their best. Implementing a robust disaster recovery plan is equally essential, giving you a clear roadmap for returning quickly from any unexpected downtime.
These best practices build a solid foundation for a scalable, resilient infrastructure. With these strategies in place, your servers become more than just tools—they transform into vital assets that actively drive your business objectives. This ensures that your operations are reliable, secure, and consistently high-performing, enabling your team to work efficiently and your customers to enjoy seamless experiences every day.
Frequently Asked Questions
What is the difference between proactive and reactive server management?
Proactive server management focuses on preventing issues before they occur through monitoring, regular maintenance, and automated alerts. Reactive management, on the other hand, involves addressing issues only when they arise. Proactive management helps reduce downtime and improve overall server reliability.
How do I know if a server is overloaded?
Indicators of an overloaded server include high CPU usage, slow response times, frequent timeouts, and increased error logs. Monitoring tools can help track these metrics and alert you when thresholds are exceeded.
How does load balancing work?
Load balancing distributes incoming network traffic across multiple servers, ensuring no single server becomes a bottleneck. This improves performance and reliability, especially during high-traffic periods. It's ideal for organizations experiencing frequent spikes in usage or growing traffic.
What's the purpose of server patching, and how often should it be performed?
Server patching involves applying updates or fixes to server software, enhancing security, and fixing bugs. Patching is essential to protect servers from vulnerabilities, and it’s generally recommended to apply patches monthly or as soon as they’re released for critical updates.
How does virtualization benefit server management?
Virtualization allows multiple virtual servers to run on a single physical server, increasing efficiency and flexibility. This makes it easier to allocate resources, scale as needed, and manage applications, while also reducing hardware costs and improving disaster recovery options.