In today’s modern, technology-driven world, even minor disruptions in IT infrastructure can significantly impact customer experiences and potentially compromise business continuity, resulting in substantial financial losses. These risks underscore the importance of implementing an effective infrastructure monitoring strategy within organizations.
Infrastructure monitoring involves continuously tracking the availability and performance of various components within your IT environment — such as servers, networks, databases, and applications. This proactive approach ensures that systems are running smoothly and can help prevent minor issues from escalating into significant problems, thereby maintaining system performance and reliability.
This blog post aims to provide you with best practices for effective infrastructure monitoring. By adopting these strategies, you'll enhance the resilience and efficiency of your IT operations, ensuring your systems stay robust and reliable, even in the face of changing business demands.
Establishing monitoring objectives
Setting clear monitoring objectives is the foundation of a focused and effective infrastructure monitoring strategy. With well-defined goals, you can navigate the complex world of data interpretation, metric tracking, and response prioritization. Establishing clear objectives is fundamental in aligning your monitoring efforts with your organization’s IT and business objectives. This alignment empowers you to manage your infrastructure adeptly and proactively address any issues that may arise.

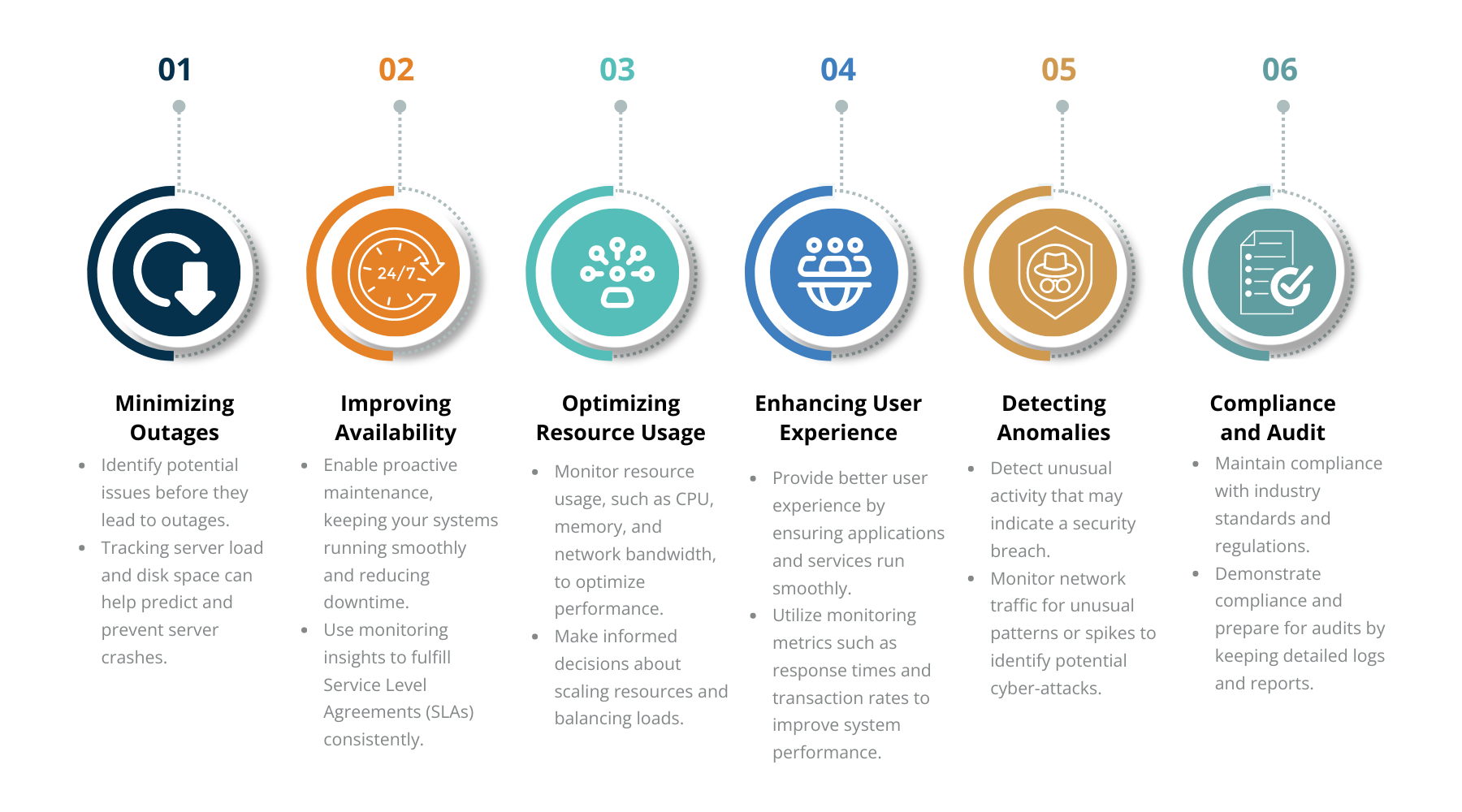
Figure 1: Infrastructure Monitoring Common Goals
Common goals
Here are some common goals to consider:
-
Minimizing outages: One of the primary goals of infrastructure monitoring is to reduce downtime. By continuously monitoring system health and performance, you can identify potential issues before they lead to outages. For instance, tracking server load and disk space can help predict and prevent server crashes.
-
Improving availability: Monitoring tools can alert IT teams, allowing for quick resolution and minimizing the impact on users and operations. By identifying potential issues before they escalate, these tools enable proactive maintenance, keeping your systems running smoothly and reducing downtime.
-
Optimizing resource usage: Monitoring resource usage, such as CPU, memory, and network bandwidth, can help optimize performance. You can make informed decisions about scaling resources and balancing loads by identifying bottlenecks and underutilized resources.
-
Enhancing user experience: Performance monitoring helps ensure that applications and services run smoothly, providing a better user experience. Utilizing metrics such as response times and transaction rates can indicate areas where performance improvements are needed.
-
Detecting anomalies: Monitoring can play a vital role in security by detecting unusual activity that may indicate a security breach. For example, monitoring network traffic for unusual patterns or spikes can help identify potential cyber-attacks.
-
Compliance and audit: Regular monitoring is essential for maintaining compliance with industry standards and regulations. Organizations can demonstrate compliance and prepare for audits by keeping detailed logs and reports.
Establishing clear monitoring objectives helps focus your efforts on what matters most to your organization. Whether it's reducing downtime, improving performance, or ensuring security, having defined goals enables your IT team to manage the infrastructure and respond swiftly to any issues proactively.
Choosing the right infrastructure monitoring tools is critical for ensuring that your monitoring efforts are effective and aligned with your organizational needs.

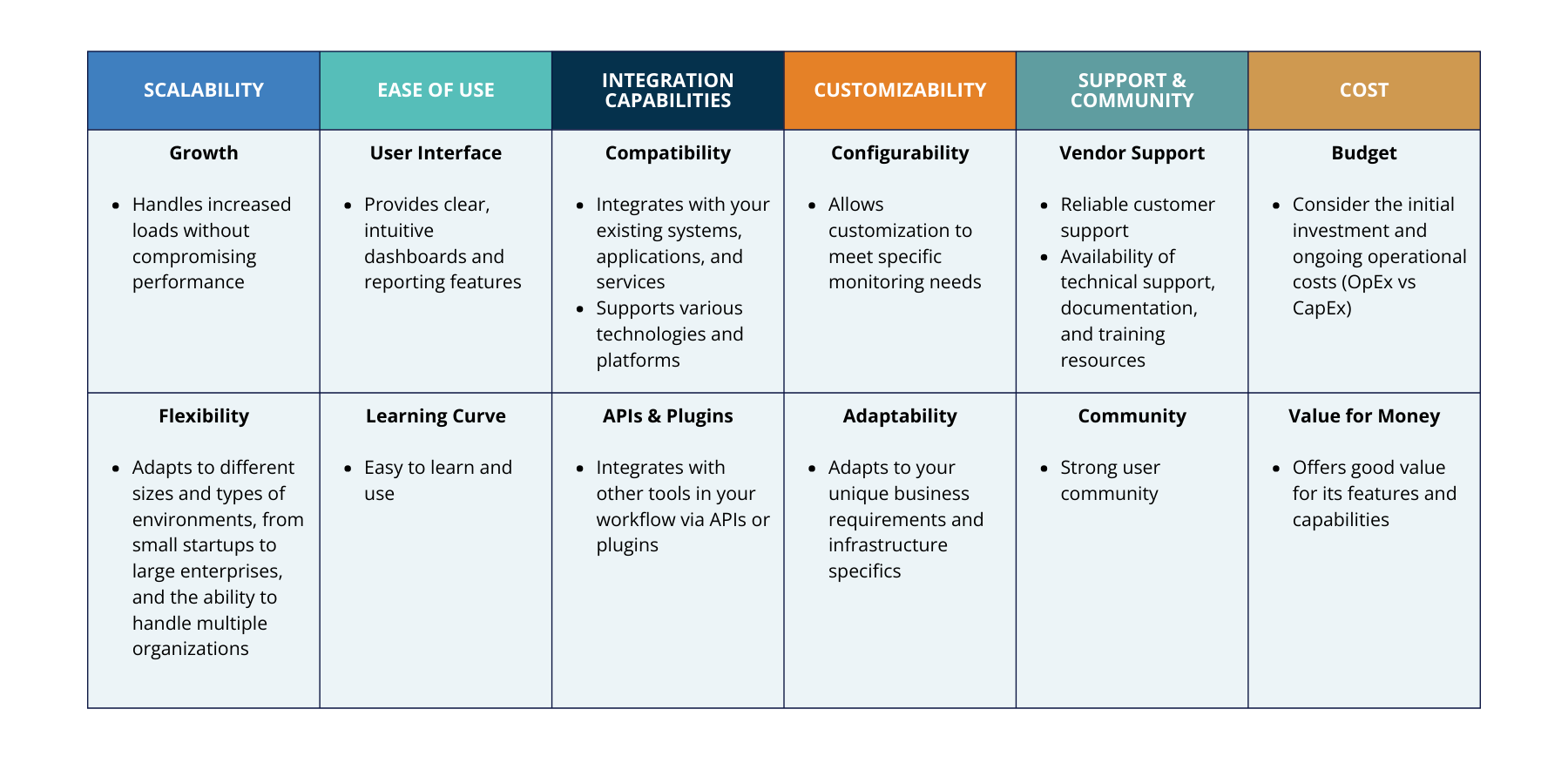
Figure 2: Infrastructure Monitoring Tools Criteria
Here are some key criteria to consider:
-
Scalability
-
-
Growth: The tool should be able to scale with your infrastructure as it grows. It should handle increased loads, such as more applications, systems, and expanded geographical locations, without compromising performance.
-
Flexibility: Consider if the tool can adapt to different sizes and types of environments, from small startups to large enterprises, and the ability to handle multiple organizations (such as additional companies through mergers, acquisitions, and Managed Services Providers (MSPs) with multiple end-customers).
-
Ease of use
-
-
User interface: The tool should provide clear, intuitive dashboards and reporting features, which make for a user-friendly experience.
-
Learning curve: The tool should be easy to learn and use, minimizing the time and resources required for training your team.
-
Integration capabilities
-
-
Compatibility: Ensure the tool integrates seamlessly with your existing systems, applications, and services. It should support various technologies and platforms you use.
-
APIs and plugins: Check if the tool offers APIs or plugins to extend functionality and integrate with other tools in your workflow.
-
Customizability
-
-
Flexibility: The tool should allow customization to meet specific monitoring needs, including custom metrics, alerts, and dashboards.
-
Adaptability: It should adapt to your unique business requirements and infrastructure specifics.
-
Support and community
-
-
Vendor support: Reliable customer support from the tool provider is essential. Check for availability of technical support, documentation, and training resources. For SaaS offerings, online and 24/7 support capabilities can extend the capabilities of your own monitoring/operations team.
-
Community: A strong user community can be a valuable resource for troubleshooting, sharing best practices, and continuous learning.
-
Cost
-
-
Budget: Evaluate the tool's cost against your budget. Consider the initial investment and ongoing operational costs, particularly Operational Expenses (OpEx) vs. Capital Expenditures (CapEx).
-
Value for money: Ensure the tool offers good value for its features and capabilities.
By selecting the right tools based on these criteria, you can ensure that your infrastructure monitoring setup is effective and aligned with your organization's needs.
Implementing comprehensive infrastructure monitoring
Comprehensive infrastructure monitoring requires a full-stack approach, covering every layer of your IT environment. Full-stack monitoring ensures you have visibility into all aspects of your infrastructure, allowing you to detect and address issues promptly, no matter where they arise. This holistic approach involves monitoring the following:
-
Hardware: Keep track of physical components like servers, storage devices, and network hardware. Monitoring hardware health can help you identify overheating, hardware failures, and capacity limits.
-
Operating systems: Monitor operating systems' performance and health to ensure they run optimally. Key aspects include tracking system resource utilization, process management, and operating system-level errors.
-
Applications: Application Performance Management (APM), like IT-Conductor, ensures that applications function correctly and efficiently. This includes monitoring application-specific metrics, response times, error rates, and transaction volumes.
-
Network: Network monitoring is essential for maintaining connectivity and performance. It involves tracking metrics such as bandwidth usage, latency, packet loss, and network errors.
By implementing full-stack monitoring, you can gain a complete view of your IT environment and ensure that all components work together harmoniously and efficiently.
Key Metrics
To effectively monitor your infrastructure, it is important to identify and track critical performance metrics.

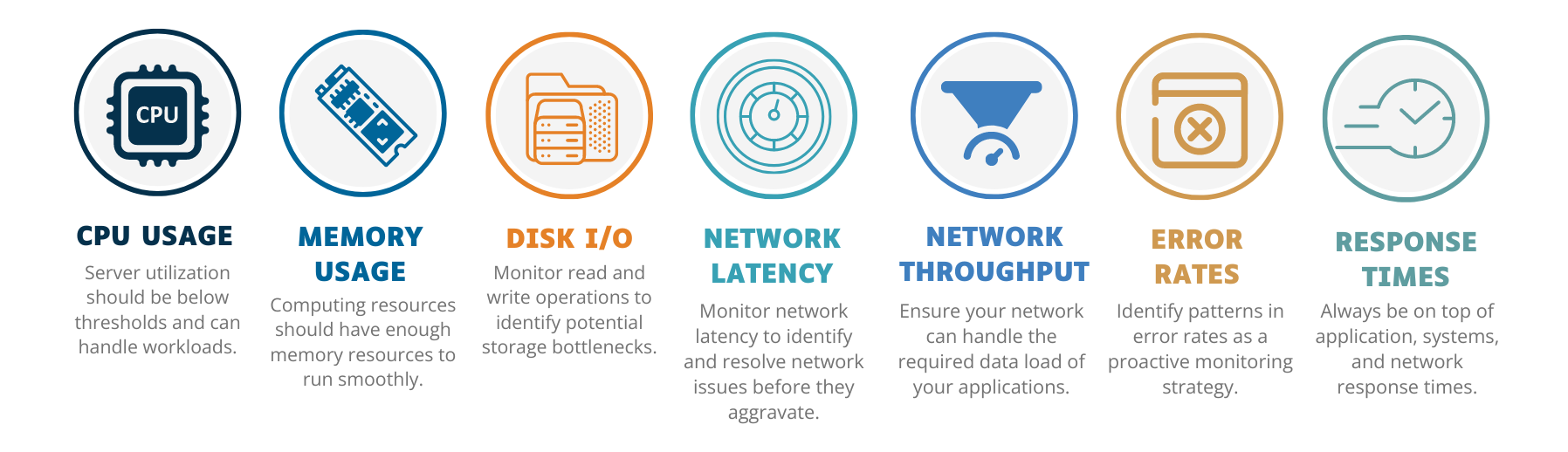
Figure 3: Infrastructure Monitoring Key Metrics
Here are some key metrics to consider:
-
CPU usage: High CPU usage can indicate resource contention and potential performance bottlenecks. Monitoring CPU usage helps you ensure your servers are not overloaded and can handle the workload.
-
Memory usage: Monitoring memory usage is crucial for preventing memory leaks and ensuring applications have enough resources to operate smoothly. High memory usage can lead to slow performance and system crashes.
-
Disk I/O: Disk input/output (I/O) metrics measure your storage devices' read and write operations. High disk I/O can indicate disk contention and affect overall system performance. Monitoring these metrics helps identify potential storage bottlenecks.
-
Network latency: Network latency measures the time data travels from one point to another in your network. High latency can lead to poor application performance and slow response times. Monitoring network latency helps identify and resolve network issues.
-
Network throughput: This metric measures the amount of data transferred over the network in a given time period. Monitoring throughput helps ensure your network can handle the required data load.
-
Error rates: Tracking the frequency of errors in your applications and systems is essential for identifying performance and reliability issues. High error rates can indicate problems that need immediate attention.
-
Response times: Monitoring response times for applications and services helps ensure they perform as expected. Slow response times can negatively impact user experience and indicate underlying performance issues.
Focusing on these key metrics can help you maintain a high level of performance, quickly identify and address potential issues, and ensure the overall health of your infrastructure. Comprehensive monitoring, covering every layer of your stack and focusing on critical metrics, is essential for maintaining system reliability and performance.
Establishing monitoring baselines
Establishing performance baselines is crucial for understanding what constitutes "normal" behavior for your infrastructure. A baseline represents a set of performance metrics captured under typical operating conditions, serving as a reference point against which future performance can be compared.
-
Understanding normal operations: During normal operations, you can collect data on CPU, memory, disk I/O, network latency, and other key metrics to determine your systems' standard performance levels. This helps you understand each infrastructure component's expected range of performance and capacity.
-
Creating historical context: Baselines provide historical context that can be invaluable for troubleshooting and performance tuning. They help you understand how your systems typically behave under different loads and conditions, providing a benchmark for evaluating changes in performance.
-
Capacity planning: Knowing your normal performance levels, you can better predict when to scale resources or adjust infrastructure to accommodate growth or increased demand.
Anomaly detection
Baselines are essential for detecting anomalies and potential issues within your infrastructure. You can quickly identify deviations that may indicate problems by comparing current performance metrics to established baselines.
-
Identifying deviations: Anomalies are often signaled by performance metrics that deviate significantly from the baseline. For instance, a sudden CPU usage spike or a network throughput drop could indicate a performance issue or an impending failure. Baselines help you differentiate between normal variability and true anomalies that require attention.
-
Proactive issue resolution: Detecting anomalies early allows you to address potential issues before they escalate into significant problems. For example, if memory usage consistently exceeds baseline levels, you can investigate and resolve the underlying cause before it leads to system crashes or degraded performance.
-
Enhanced security monitoring: Baselines are also useful for security monitoring. Unusual patterns in network traffic, unexpected spikes in resource usage, or deviations in application behavior can indicate security breaches or malicious activities. By monitoring for deviations from the baseline, you can enhance your security posture and respond more quickly to potential threats.
-
Fine-tuning alerts: Baselines help in fine-tuning alert thresholds. By understanding normal performance levels, you can set more accurate thresholds for alerts, reducing false positives and ensuring that you are notified of genuine issues that require intervention.
Setting up alerts and notifications
Setting up alerts and notifications is crucial for maintaining system health and responding promptly to issues. These proactive measures ensure that IT teams are immediately informed of any anomalies, allowing them to take swift action before small problems become major disruptions.

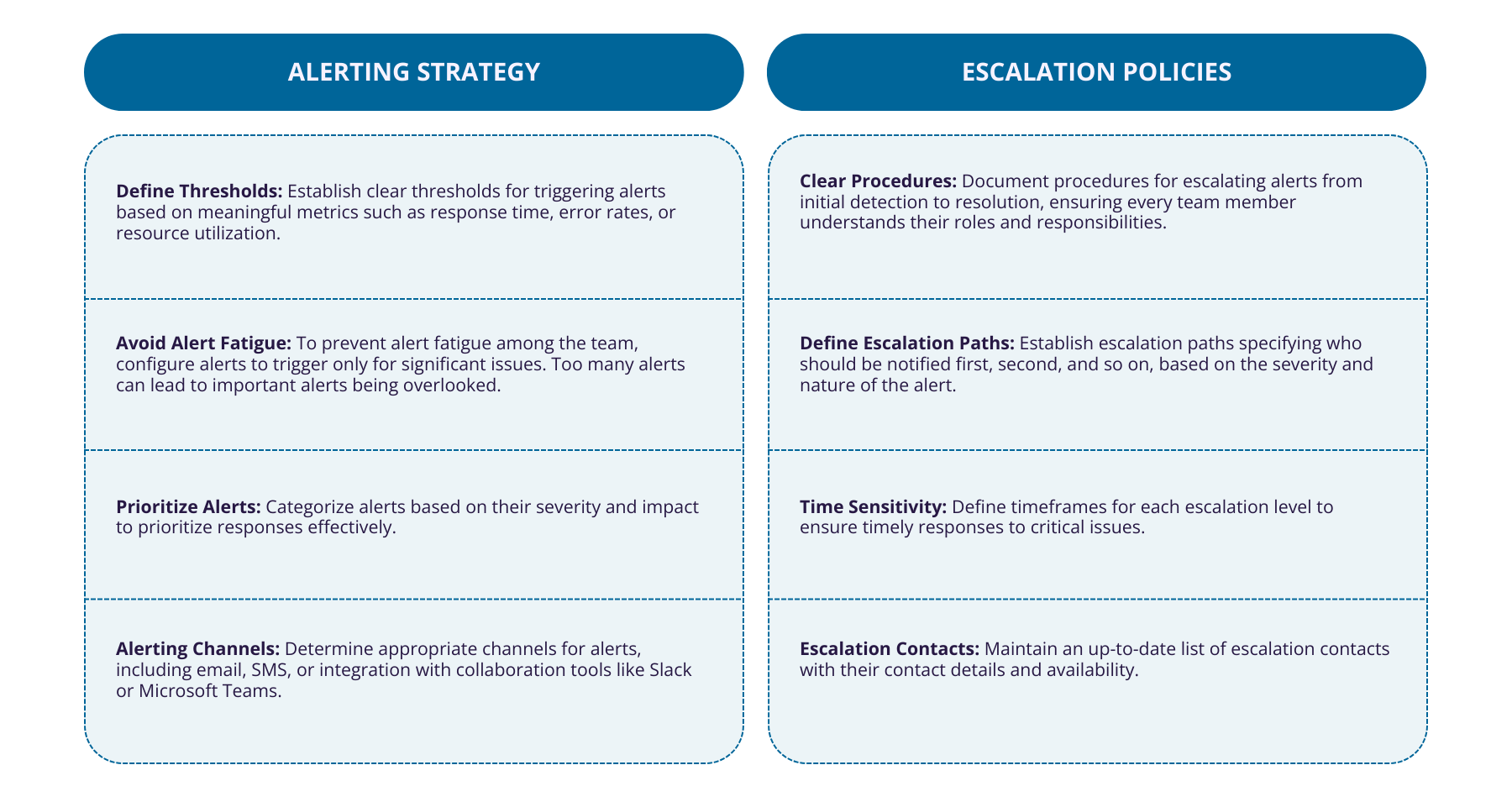
Figure 4: Alerting Strategy vs Escalation Policies
Alerting strategy
Here are key considerations for effective alerting and escalation policies:
-
Define thresholds: Establish clear thresholds for triggering alerts based on meaningful metrics such as response time, error rates, or resource utilization.
-
Avoid alert fatigue: To prevent alert fatigue among the team, configure alerts to trigger only for significant issues. Too many alerts can lead to important alerts being overlooked.
-
Prioritize alerts: Categorize alerts based on their severity and impact to prioritize responses effectively.
-
Alerting channels: Determine appropriate channels for alerts, including email, SMS, or integration with collaboration tools like Slack or Microsoft Teams.
Escalation policies
-
Clear procedures: Document procedures for escalating alerts from initial detection to resolution, ensuring every team member understands their roles and responsibilities.
-
Define escalation paths: Establish escalation paths specifying who should be notified first, second, and so on, based on the severity and nature of the alert.
-
Time sensitivity: Define timeframes for each escalation level to ensure timely responses to critical issues.
-
Escalation contacts: Maintain an up-to-date list of escalation contacts with their contact details and availability.
Effective alerting and escalation policies ensure that teams promptly respond to issues, minimizing downtime and maintaining system reliability.
Regularly reviewing and updating monitoring strategies
Maintaining an effective monitoring strategy requires ongoing evaluation and adjustment to keep up with evolving systems and technologies.
Continuous improvement
-
Regular assessments: Schedule periodic reviews of your monitoring strategies to assess their effectiveness. This helps identify gaps and areas for improvement.
-
Feedback loops: Establish feedback loops where insights from incident reports, performance reviews, and team feedback are used to refine monitoring practices.
-
Performance metrics: Evaluate the metrics and KPIs monitored to ensure they align with business objectives and current system priorities.
Adapting to changes
-
Infrastructure changes: Update monitoring tools and strategies to accommodate infrastructure changes, such as scaling up resources, migrating to the cloud, or integrating new services.
-
New technologies: Incorporate monitoring practices for new technologies adopted by your organization, ensuring that they are adequately tracked and managed.
-
Automation and AI: Leverage advancements in automation and AI to enhance monitoring capabilities, reduce manual efforts, and improve accuracy in detecting anomalies.
Regularly reviewing and updating your monitoring strategies ensures they remain relevant and effective, helping your organization respond proactively to changes and maintain optimal system performance.
Ensuring security in monitoring
Security is paramount in monitoring activities to protect sensitive data and comply with regulatory requirements.

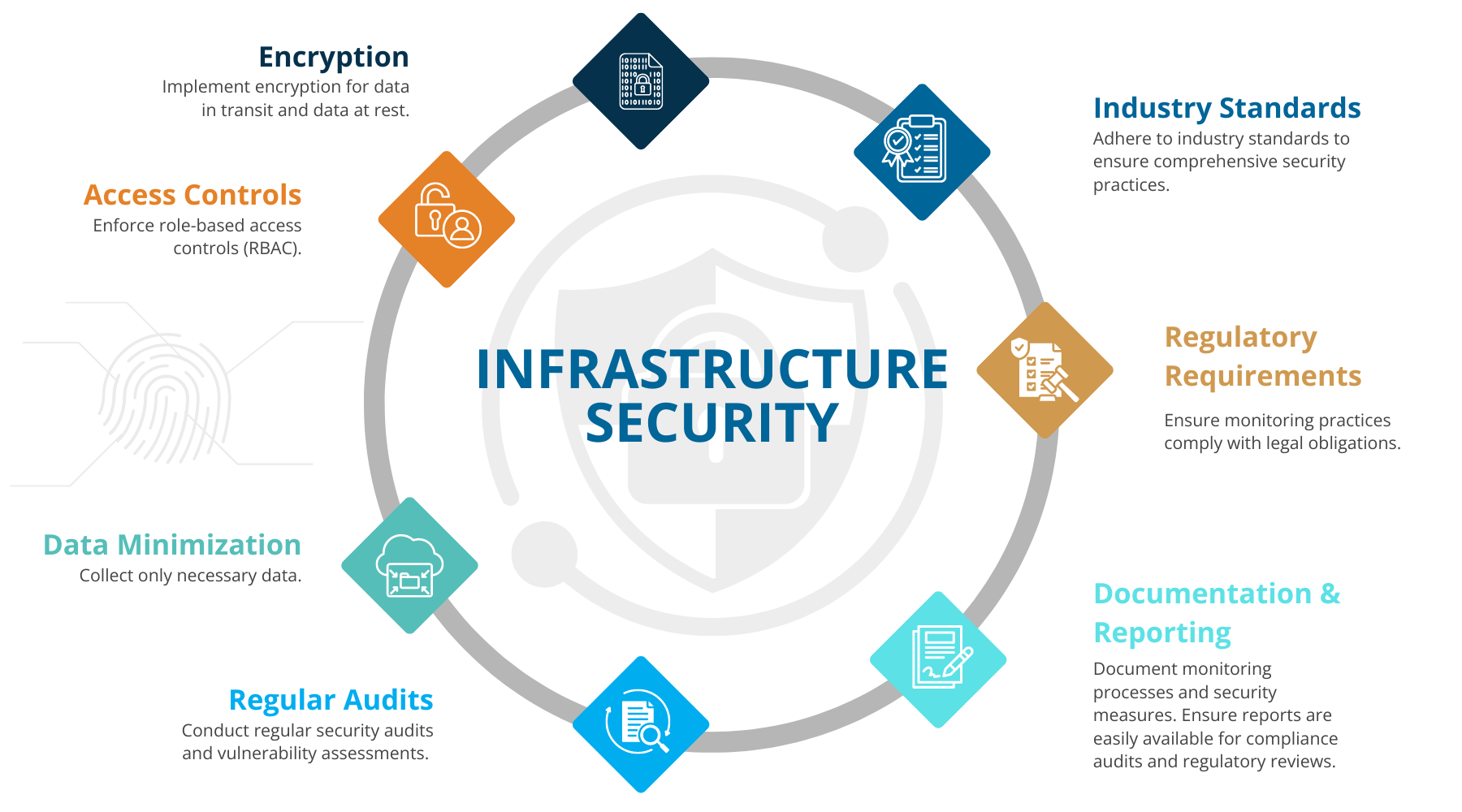
Figure 5: Infrastructure Security
Here are some considerations for ensuring security in monitoring:
-
Encryption: Implement encryption for data in transit and at rest to safeguard against unauthorized access and breaches.
-
Access controls: Establish strict access controls, ensuring only authorized personnel can view and manage monitoring data. Use role-based access controls (RBAC) to enforce these policies.
-
Data minimization: Collect only the necessary data required for monitoring purposes to reduce the risk exposure in case of a breach.
-
Regular audits: Conduct security audits and vulnerability assessments of your monitoring systems to identify and address potential security weaknesses.
-
Industry standards: Adhere to industry standards such as ISO 27001, NIST, or specific frameworks relevant to your sector (e.g., HIPAA for healthcare, PCI-DSS for payment processing) to ensure comprehensive security practices.
-
Regulatory requirements: Stay updated with relevant regulations, such as GDPR, CCPA, or other local data protection laws, to ensure your monitoring practices comply with legal obligations.
-
Documentation and reporting: Thoroughly document your monitoring processes and security measures. Ensure you can generate necessary reports for compliance audits and regulatory reviews.
Ensuring security in monitoring protects sensitive data, builds trust with stakeholders, and helps avoid legal and financial repercussions associated with non-compliance.
Leveraging automation
Incorporating automation into your monitoring strategy can significantly enhance responsiveness and efficiency.
Here are the key areas in automation that can be leveraged:
-
Immediate action: Implement automated responses to common issues, such as restarting a service, clearing a cache, or scaling resources, to minimize downtime and prevent escalation.
-
Predefined playbooks: Develop predefined playbooks for routine incidents that automation tools can execute, ensuring consistent and swift responses to recurring problems.
-
Alert enrichment: Use automation to enrich alerts with relevant context, such as historical data or recent changes, to facilitate quicker decision-making by the on-call team.
-
Reduced manual intervention: Automate repetitive tasks and routine checks, allowing your team to focus on more complex and strategic activities.
-
Consistency and accuracy: Automating monitoring and response workflows ensures consistent process application and reduces human error.
-
Scalability: Enhance scalability by allowing your monitoring system to handle increased load and complexity without a proportional increase in manual effort.
Leveraging automation improves the efficiency and effectiveness of your monitoring strategy and enables your team to respond more quickly and accurately to issues, ultimately enhancing system reliability and performance.
Training and knowledge sharing
Effective monitoring relies on well-trained teams and comprehensive documentation.
Team training and documentation
Here's how to ensure your team is knowledgeable and your monitoring setups are well-documented:
-
Regular training sessions: Conduct regular training sessions to update your team on the latest monitoring tools, features, and best practices. Include hands-on exercises to reinforce learning. These should also include regular Knowledge Transfer sessions and service reviews with the vendor.
-
Onboarding programs: Develop comprehensive onboarding programs for new team members that cover the fundamentals of your monitoring systems and protocols.
-
Cross-training: Encourage cross-training to ensure all team members are familiar with different aspects of the monitoring setup, promoting flexibility and resilience within the team.
-
Stay updated: Provide opportunities for ongoing education through webinars, workshops, and certifications to keep the team abreast of industry developments and emerging technologies.
-
Detailed documentation: Maintain detailed documentation of your monitoring setups, including architecture diagrams, configuration settings, and integration points. Ensure it is easily accessible and regularly updated.
-
Standard Operating Procedures (SOPs): Create SOPs for common monitoring tasks and incident response procedures to ensure consistency and quick reference during incidents.
-
Change logs: Keep a comprehensive log of changes made to the monitoring system, including updates, patches, and configuration adjustments, to track history and facilitate troubleshooting.
-
Knowledge base: Develop a knowledge base with articles, FAQs, and troubleshooting guides that team members can consult to resolve issues independently and efficiently.
Investing in team training and thorough documentation fosters a knowledgeable, capable team and ensures smooth, consistent monitoring operations. This enhances system reliability, reduces response times, and improves operational efficiency.
Building a robust infrastructure monitoring with IT-Conductor
Effective infrastructure monitoring is critical for maintaining system health, ensuring security, and optimizing performance. Organizations can create a robust monitoring framework by judiciously setting up alerts and notifications, regularly reviewing and updating monitoring strategies, ensuring security in monitoring, leveraging automation, and prioritizing team training and knowledge sharing.
Implementing these best practices will enhance the reliability and efficiency of your infrastructure and empower your team to respond quickly and effectively to any issues. We encourage you to integrate these strategies into your monitoring processes to achieve optimal performance and resilience in your systems. Start today by evaluating your current practices and identifying areas for improvement — your infrastructure's health and your team's productivity depend on it.
Frequently Asked Questions