In our last blog post 'Agent-based vs Agentless Monitoring', we explored the important differences between agent-based and agentless monitoring. We talked about how agentless monitoring can be a game-changer for your IT setup. It's not just about using fewer resources or making deployment easier. It's about giving you more control and peace of mind when it comes to keeping your systems secure and compliant.
Now, we want to take things a step further. We're going to walk you through the process of getting your infrastructure ready for agentless monitoring. We'll also share some tips on how to make it work smoothly in your specific environment. Whether you're new to this or looking to optimize your current setup, we've got you covered. Let's dive in and explore how you can make agentless monitoring work for you!
To successfully implement agentless monitoring, we’ve broken down this section into preparation and implementation.
Prepare Your IT Infrastructure
This section involves setting clear objectives, identifying compatible devices, defining the most appropriate metrics, and choosing a robust tool to support your monitoring needs. By laying a solid foundation, you’ll ensure that your agentless monitoring setup is accurate, efficient, and ready to scale as your infrastructure evolves. Here’s how to get started.
Step 1: Define Monitoring Goals
Clear objectives help you focus on the most critical metrics, align with business needs, and ensure efficient resource use. This focus ultimately leads to faster response times, better allocation of IT resources, and more meaningful data that informs decision-making and enhances infrastructure resilience. Before setting up an agentless monitoring solution, clarify your objectives. Ask yourself:
-
What telemetry by application, do you need to monitor? (e.g., CPU usage, memory, uptime)
-
What are the critical devices or services/applications?
-
How quickly should issues be detected and resolved?
-
Which performance benchmarks should your systems meet to align with business expectations, such as Service Level Agreement (SLA) for your customers, as well as Operational Level Agreement (OLA) for your internal IT team?
-
Who is responsible for addressing alerts, and what are the established response procedures?
Step 2: Identify Devices
Decide which network devices, servers, and applications you want to monitor and evaluate their compatibility with agentless monitoring protocols like SNMP, WMI, and SSH for Linux Systems, or ODBC/JDBC for databases. Here are some examples of devices you’ll want to consider:
-
Firewalls and Security Appliances: Monitoring these for unusual traffic patterns, CPU load, and log events can alert you to potential security issues.
-
Servers (Physical and Virtual): Metrics like CPU and memory usage, disk I/O, and uptime are key to identifying performance bottlenecks and preventing downtime.
-
Databases: Monitor query response times, connection counts, and error logs to maintain data availability and performance.
-
Applications and Web Servers: Monitoring response times, HTTP errors, and transaction volumes can help ensure a positive user experience.
-
Cloud Services and Virtual Machines: If you have cloud infrastructure, monitoring instances, resource usage, and service status (e.g., for AWS, Azure) allows you to track costs, performance, and availability.
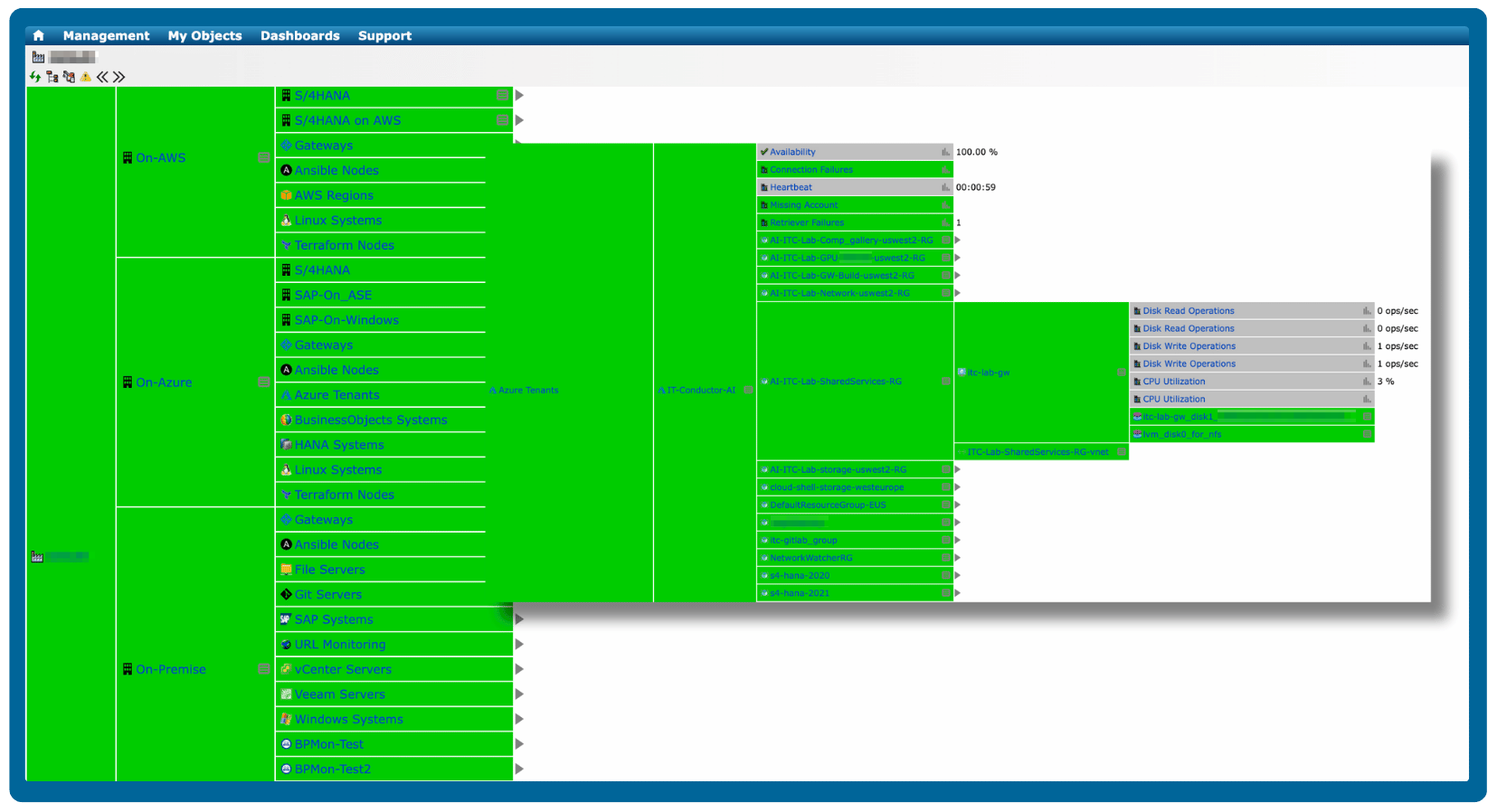
 Figure 1: Azure Monitoring in IT-Conductor
Figure 1: Azure Monitoring in IT-Conductor

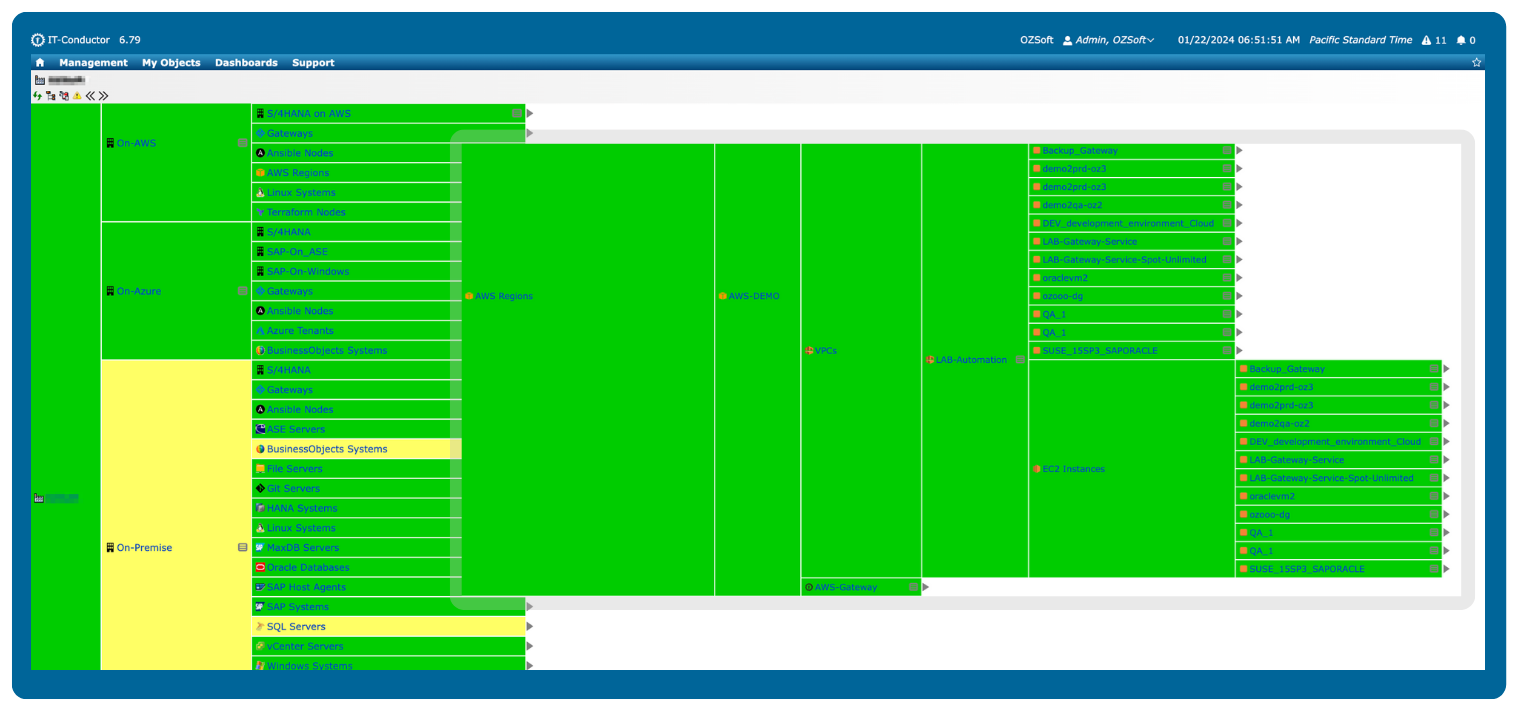
Figure 2: AWS Monitoring in IT-Conductor
Step 3: Define Metrics
Identify the key performance indicators (KPIs) and metrics you need to track. Common metrics in agentless monitoring include:
-
Bandwidth Usage: Bandwidth usage measures the volume of data transferred over a network in a given time. High bandwidth usage can indicate congestion, bottlenecks, or even potential security risks.
-
Latency: By tracking latency, you can identify areas of delay in your network and work on optimizing communication paths, especially in environments where low-latency performance is critical (e.g., VoIP, video streaming).
-
CPU Utilization: Monitoring CPU usage helps ensure that devices aren’t overwhelmed, allowing you to distribute workloads more effectively and avoid service interruptions.
-
Memory Utilization: This metric tracks how much memory (RAM) is being used by device. Insufficient memory can lead to slower response times, swapping, and in some cases, system crashes.
-
Disk Usage and I/O Performance: High disk usage or I/O latency can impact data access and application performance. Monitoring these metrics helps you plan for storage upgrades and detect storage issues before they impact users.
-
Network Throughput: Monitoring throughput can help you identify bottlenecks and ensure that your infrastructure is capable of supporting high-traffic demands, which is critical for business continuity and scaling.
-
Uptime and Availability: Uptime measures the amount of time a device or service is operational. Availability ensures that critical services are accessible to users when needed.
-
Application Response Time: Application response time measures how quickly applications respond to user requests, from the point of request to the data delivery.
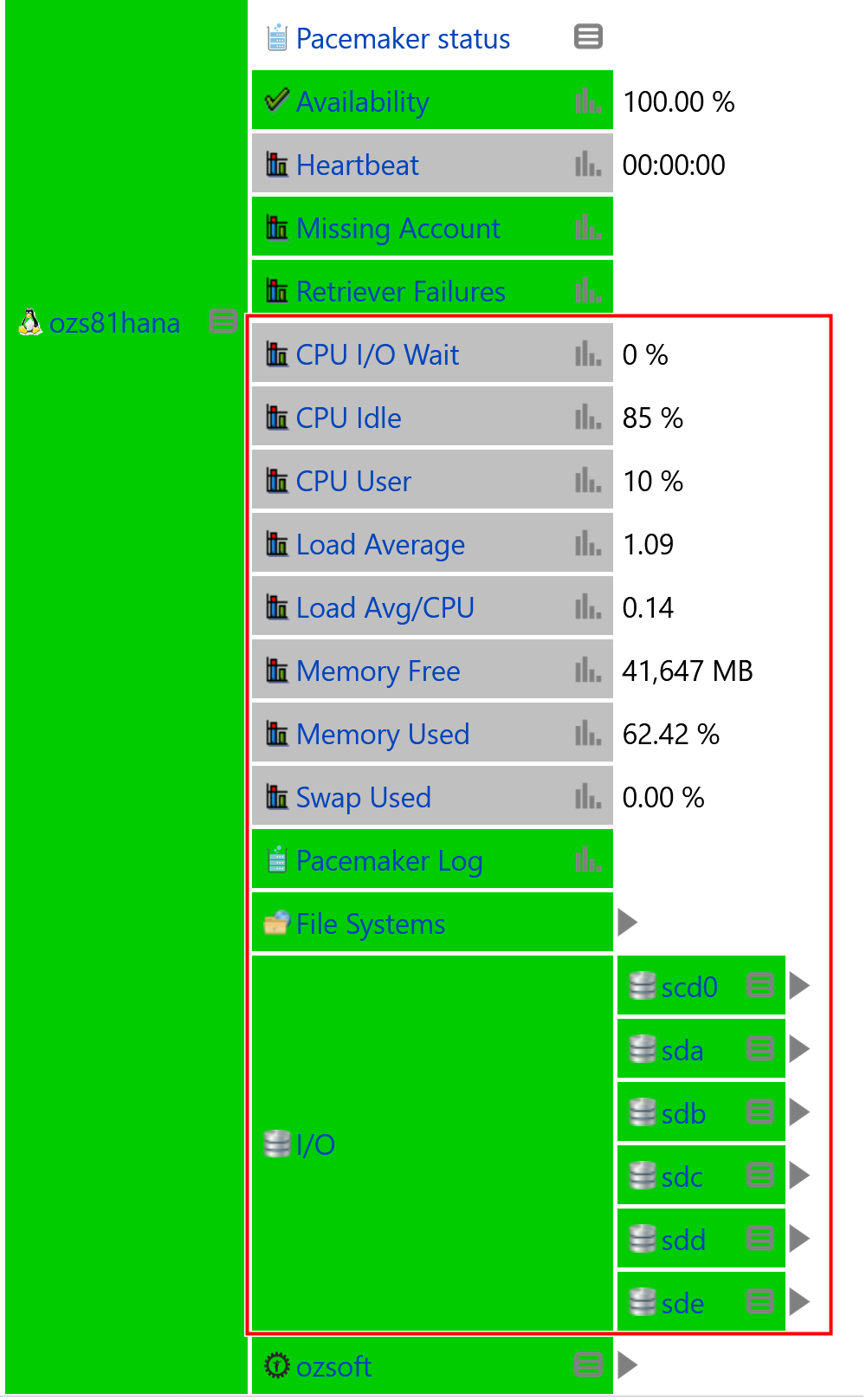
 Figure 3: Monitoring Metrics in IT-Conductor
Figure 3: Monitoring Metrics in IT-Conductor
Related blog post: Top 10 Things to Check for Continuous SAP Monitoring
Now that you know exactly what your organization needs to monitor, the final item on our preparation checklist is to select a monitoring tool that supports the protocols your devices require and the metrics you need to monitor. This is typically a long process if you have to go through trials and comparisons of each solution or set of solutions, so plan it accordingly.
Look for a solution that addresses your specific monitoring needs while offering a complete agentless experience. If you recall from our previous blog post, we discussed how IT-Conductor’s platform targets the key use cases for agentless monitoring. As a bonus, IT-Conductor is compatible with the devices mentioned above, which will enable you to monitor a wide range of metrics from a single platform.
To help streamline your search, download our SAP & HANA Monitoring Tools Comparison Matrix for a detailed side-by-side comparison of top solutions.
Related blog post: How APM Automation Accelerates SAP Assessment, Performance & Migration
Step-by-step Implementation
Once you’ve prepared your infrastructure and chosen the right tools, it’s time to set up your agentless monitoring system. This section outlines a step-by-step approach to implementing agentless monitoring in your IT environment. Here’s how to put your agentless monitoring solution into action.
Agentless monitoring requires network access to the devices you want to monitor, so you’ll need to configure permissions accordingly. For SNMP-based monitoring, make sure that SNMP is enabled on network devices and that community strings (or credentials) are securely set up. Similarly, if using WMI, SSH, or ODBC/JDBC, make sure that proper access permissions are configured on servers and applications.
Step 6: Set Up Alerts and Thresholds
Alerts are an essential part of monitoring, as they notify you of issues that may require immediate action. Set up alerts with defined thresholds for each metric—CPU usage, for example, might trigger a warning at 80% and a critical alert at 95%. These thresholds should reflect the acceptable ranges for each device based on its role and load. Ensure that alerts are routed to the appropriate teams through email, SMS, or other communication channels, and adjust them as necessary to avoid alert fatigue.
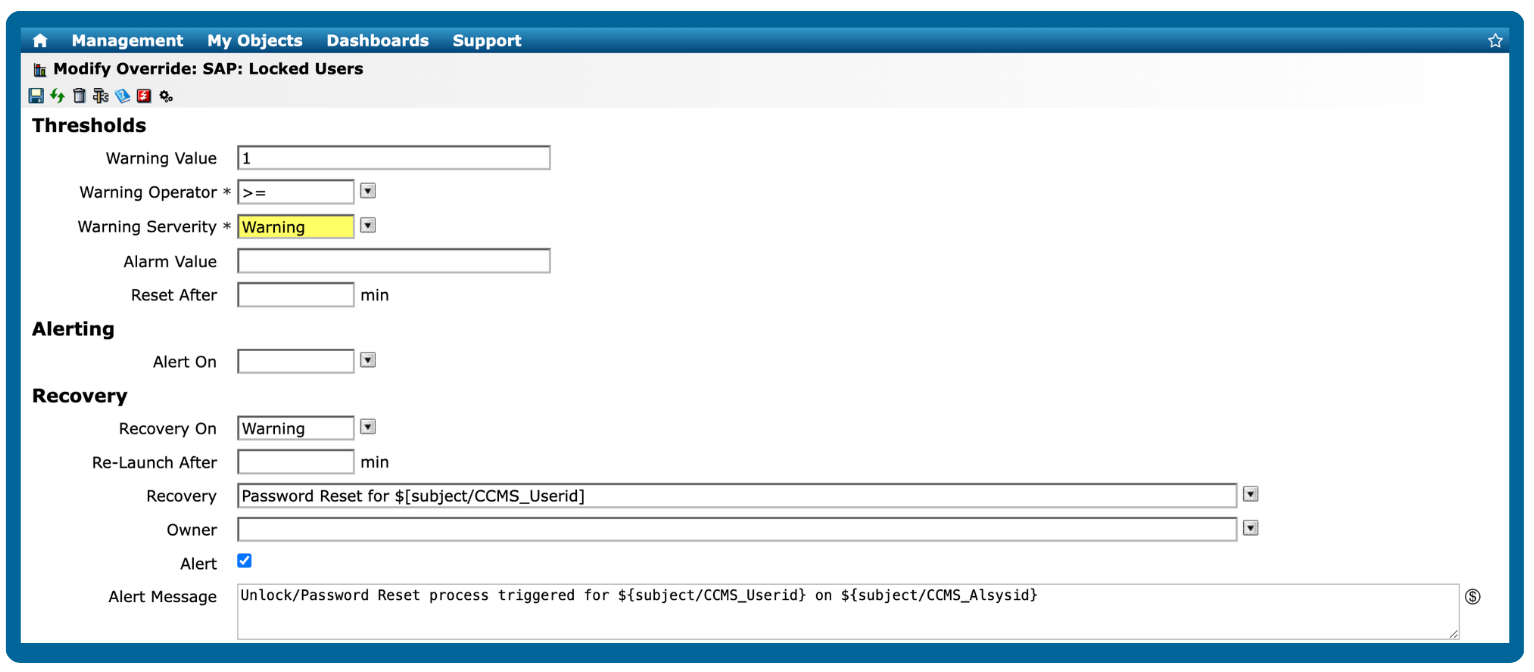
 Figure 4: Setting up alerts and thresholds in IT-Conductor
Figure 4: Setting up alerts and thresholds in IT-Conductor
Step 7: Test the Monitoring System
Before rolling out monitoring on a large scale, run a series of tests to ensure your system is configured correctly. Verify that data is being collected for each metric and that alerts trigger appropriately. Testing helps identify configuration issues, such as permissions or incorrect thresholds, that could disrupt monitoring accuracy. Conducting a dry run where simulated incidents trigger alerts is also helpful, so you can assess the end-to-end alert response process.
Step 8: Use Dashboards to Analyze Data
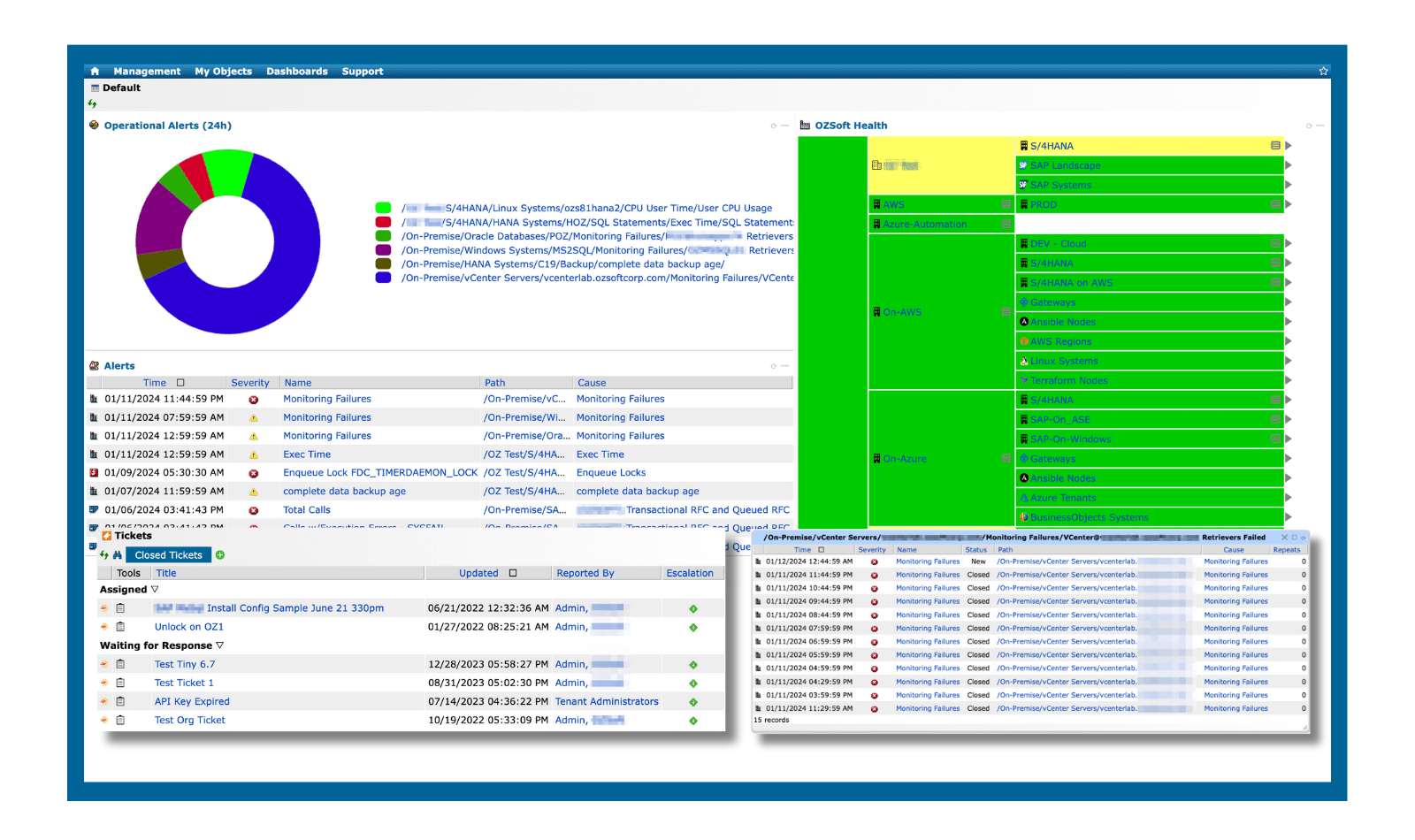
Once you’ve onboarded the desired applications, it’s time to set up dashboards to visualize the metrics you’re collecting. Collecting and analyzing data is essential for understanding your infrastructure’s performance and for making informed, data-driven decisions. Real-time dashboards, available in many monitoring tools, such as IT-Conductor, provide a global view of your system's health, allowing IT teams to observe key metrics like CPU usage and availability at a glance. Dashboards should highlight critical metrics, and present historical data for trend analysis.

Figure 5: Overview Monitoring Dashboard
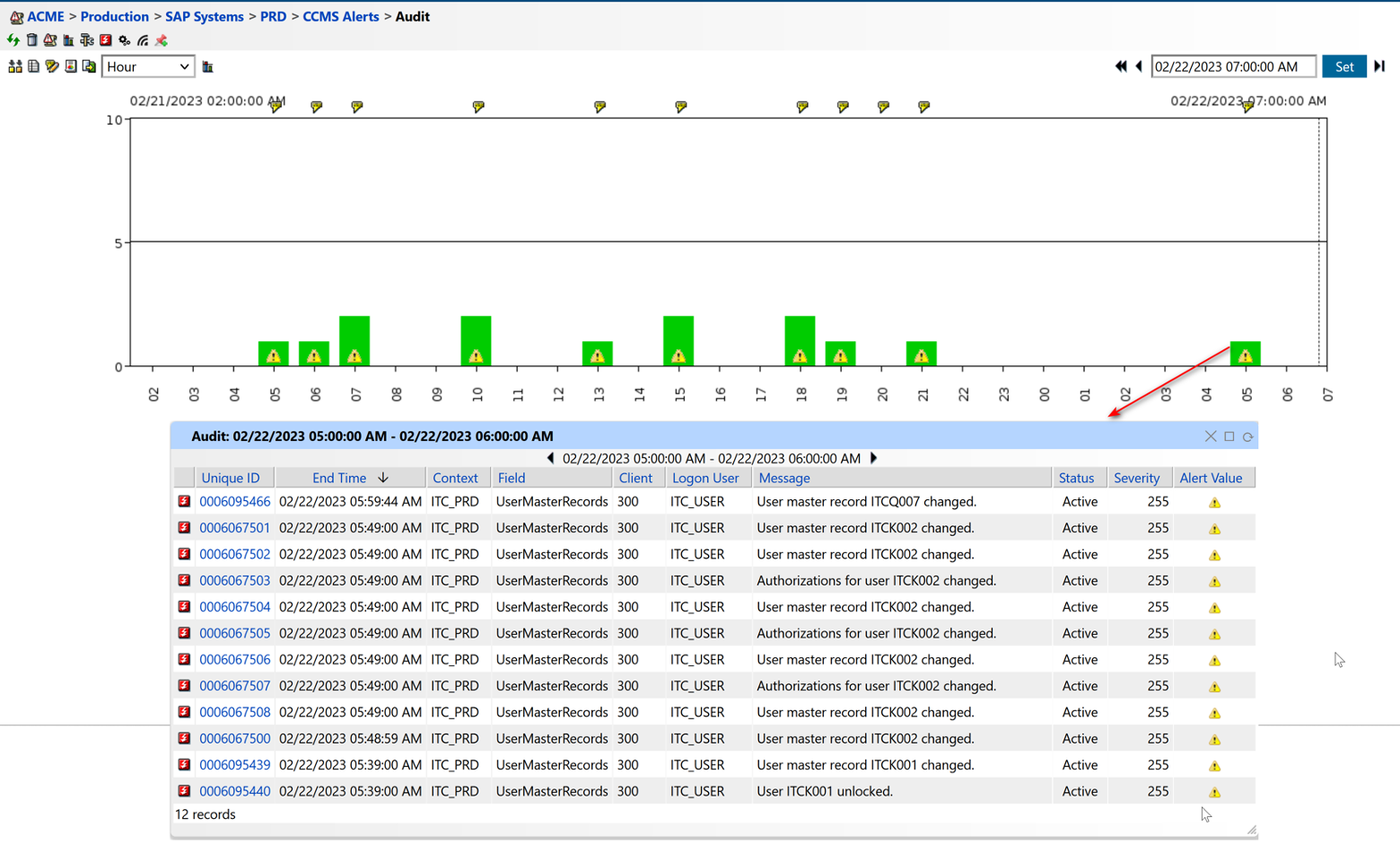
Over time, regular data analysis can reveal performance trends such as peak usage times, recurring bottlenecks, or predictable outages. Recognizing these patterns not only informs resource planning but also helps in distributing workloads more effectively, ensuring smoother operations. For example, if network latency is a priority, examining latency data across different devices can uncover where delays may be happening and guide specific optimizations. Visualizing long-term data through graphs and historical charts is equally important, as these visual tools make it easier to detect gradual trends that might otherwise go unnoticed. Furthermore, correlating data across various metrics can be highly informative. Issues are often interrelated, such as when high CPU utilization coincides with high memory usage.

Figure 6: Audit Log Monitoring
Step 9: Establish a Reporting Schedule
Regular reports are essential for keeping a pulse on your infrastructure’s performance, spotting trends, and making sure systems align with your organization’s goals. To make reporting manageable and useful, start by setting a reporting schedule that fits your monitoring needs. For critical setups where early detection is key, daily reports might be best, while other environments may do well with weekly or monthly summaries.
Alongside frequency, tailoring reports to suit different readers can make all the difference in their impact. For example, while a detailed report for the IT team might dive deep into performance metrics and specific incidents, an executive summary would focus on KPIs and key incidents in a straightforward format that management can quickly absorb.
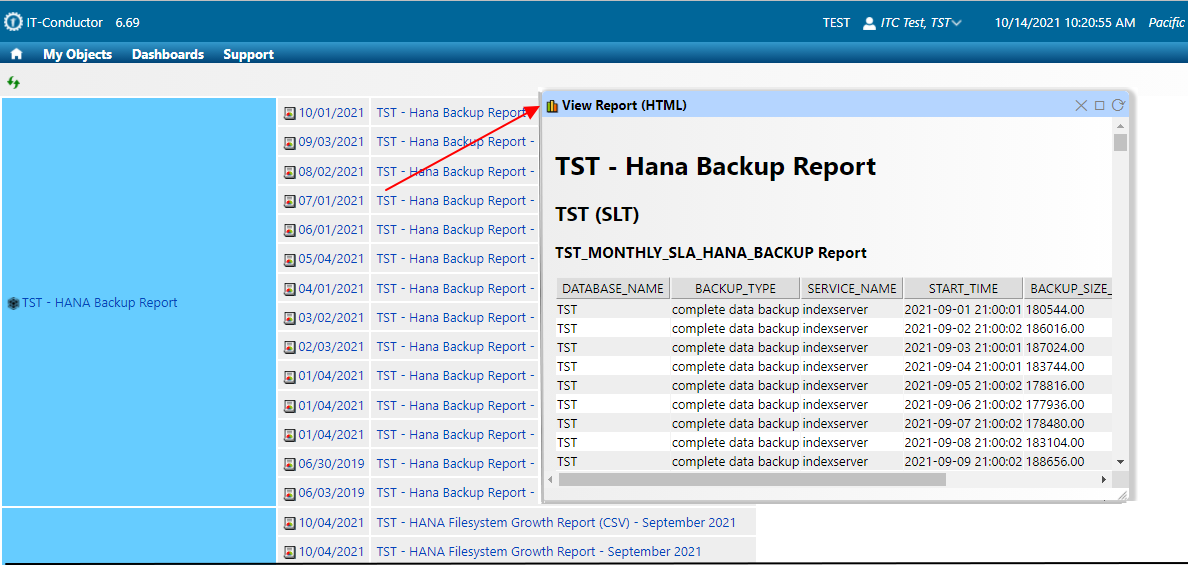
Finally, reports should highlight critical insights and anomalies, allowing teams to spot potential issues before they escalate. For instance, if performance consistently declines in a certain area, this can be flagged so the team can act quickly. For organizations with SLAs, reporting on key metrics like uptime, availability, and response times is crucial for meeting service commitments. IT-Conductor simplifies reporting by seamlessly integrating essential metrics into customizable, comprehensive reports, enabling teams to monitor compliance and maintain infrastructure health with ease. Whether you need in-depth technical data for the IT team or high-level summaries for management, IT-Conductor makes it easy to tailor reports to effectively communicate insights across the organization.

Figure 7: Online Viewing for HTML Reports
Step 10: Continuously Optimize and Scale
Last but not least, as your IT infrastructure grows, your monitoring solution should scale and adapt to it. Regularly revisiting and adjusting metrics, alert thresholds, and reporting frequencies ensures your monitoring stays relevant amid increasing workloads and complexity. Incorporate new devices, services, and applications with the right metrics and alerts to maintain consistent coverage across your expanding environment.
Automation can simplify scaling by configuring alerts, reports, and thresholds for new additions automatically, saving time and reducing human error.
Planning for growth is essential, especially if you anticipate increased traffic or resource demands. Monitoring capacity metrics like storage, CPU, and network load helps identify potential bottlenecks, allowing proactive responses. And don’t forget to make sure that your chosen monitoring tool can scale effectively. Scalable solutions designed for large environments ensure your monitoring remains robust and adaptable as your infrastructure grows.
Best Practices for Effective Agentless Monitoring
To get the most from your agentless monitoring, it’s essential to follow best practices that ensure accuracy, security, and adaptability. With the right approach, your monitoring solution can do more than just track performance—it can empower your team to stay ahead of issues, optimize resources, and drive efficiency as your infrastructure grows. Here are some key practices to help you optimize your agentless monitoring setup.
-
Regular Audits: Perform regular audits to ensure your monitoring solution is up-to-date, devices are correctly configured, and protocols are secure. Audits help verify data accuracy and identify any monitoring gaps.
-
Optimize Alert Settings: Fine-tune alerts to reduce noise and ensure actionable insights. This can help your team avoid alert fatigue and focus on issues that genuinely require attention.
-
Secure Access and Data: Agentless monitoring reduces the attack surface, but security remains critical. Use encrypted protocols, like HTTPS, to safeguard data in transit.
-
Continuous Improvement: The infrastructure you monitor will evolve, and your monitoring system should evolve, too. Regularly review insights to identify areas for performance optimization and adapt to new challenges.
Conclusion
Agentless monitoring is a powerful way to streamline your IT infrastructure monitoring, reducing resource usage, and simplifying management. By setting clear goals, choosing the right tool, and following a structured implementation process, you can ensure efficient and effective infrastructure monitoring. Regularly auditing and optimizing your setup will help you maintain peak performance, providing actionable insights and minimizing downtime.
Agentless monitoring provides an adaptable, low-overhead solution for dynamic IT environments. Ready to get started? Explore IT-Conductor’s capabilities by scheduling a free demo to see how agentless monitoring can support your IT infrastructure and help achieve your monitoring goals.
Frequently Asked Questions