IT-Conductor focused this quarter on increasing the ROI for our customer's daily SAP Operations by automating the management of critical areas to minimize disruptions in services and maximizing the availability and performance of systems:
- Pacemaker Cluster Resource Management
- Linux Kernel Resource Management
- HANA Memory Management
- HANA Automated Backup
- SAP qRFC Inbound and Outbound Queue Management
- Printer Queue Management
- SAP Jobs Management
- SAP System Performance Reporting
- Daily Recovery Reports
- Service Operations for SAP/DB/OS/VM stop/start
A few of these newly added features include:
1. Pacemaker Cluster Resource Management
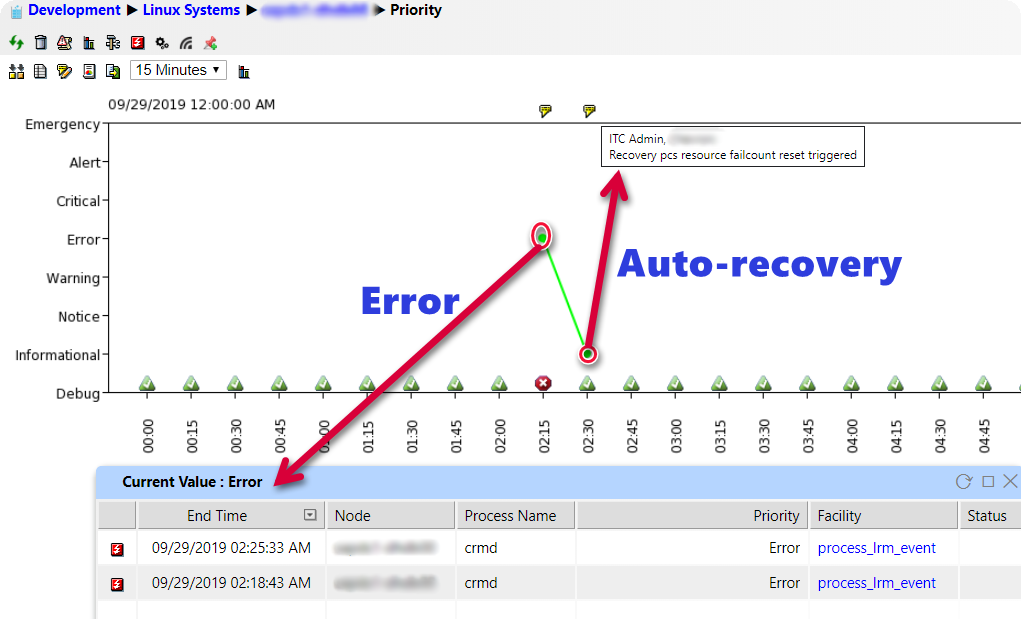
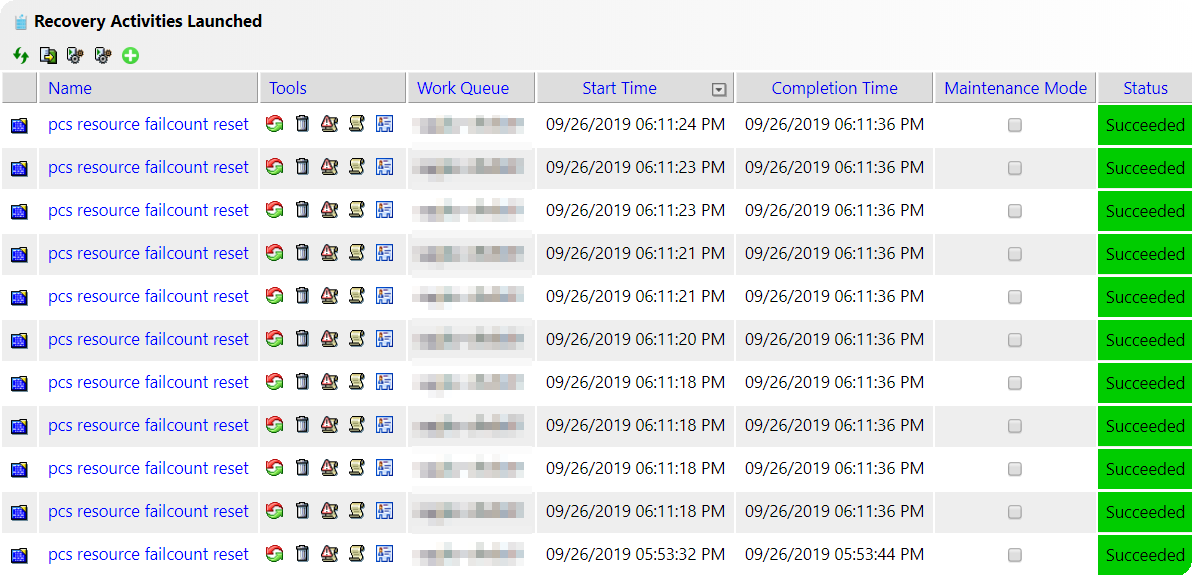
In Q2-2019, IT-Conductor introduced Pacemaker HA Cluster Monitoring, which has been enhanced to allow the detection of many types of cluster events and logs, that can be matched to a specific resource or engine errors. In Pacemaker, the resource fail count keeps track of errors in operation such as start, stop, and monitor for every resource managed by the cluster. These fail counts are often the result of soft errors such as timeout during the startup of resources, which can take longer depending on system size, e.g. HANA startup can be longer on a large system. Thus, it is not desirable to trigger resource recovery or failover which can be simply retried. IT-Conductor can monitor these resource failures and trigger auto-recovery to reset the fail count (back to zero) so that the cluster can retry the operations which often succeed, otherwise, a failover may occur. Meanwhile, the original reason for the failure could still be alerted and notified so the underlying cause can be further investigated.
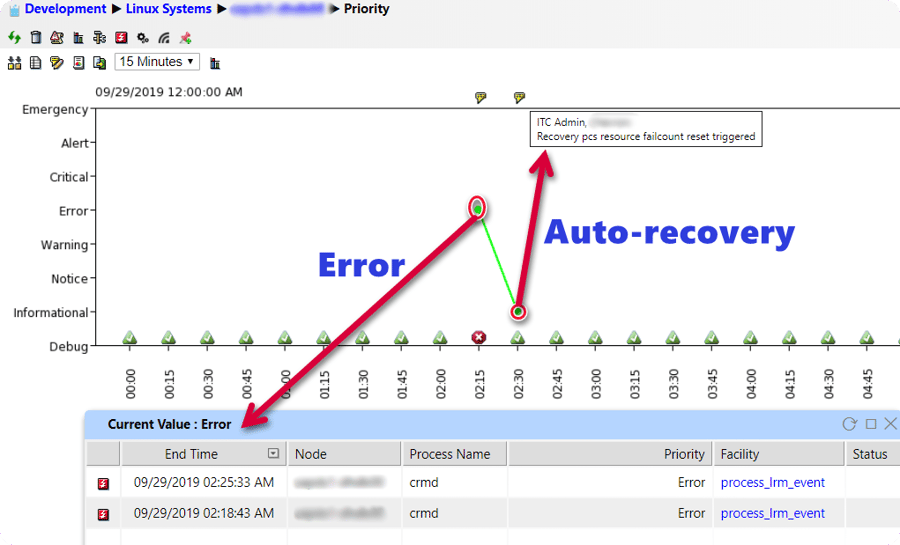
Figure 1: Pacemaker Cluster Resource Management
2. Linux Kernel Resource Management
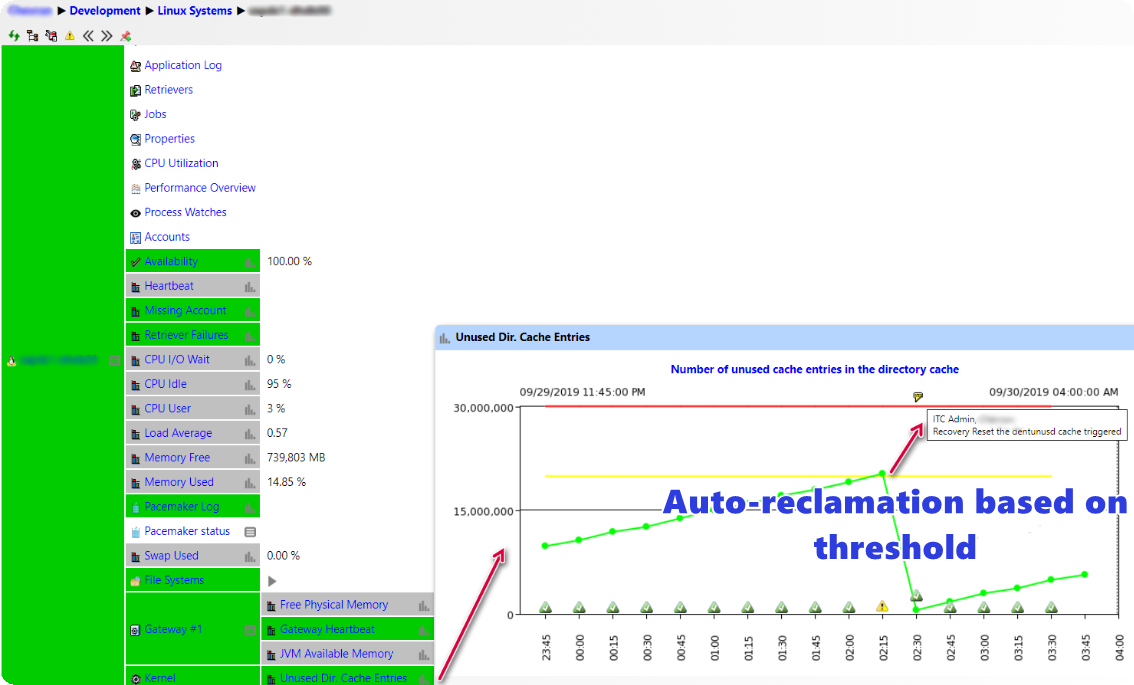
In Q2-2019, IT-Conductor also introduced Linux Monitoring Enhancements, including kernel usage monitoring of critical resources like processes, threads, and memory usage. While these are useful for capacity and tuning, there is often a need to proactively manage the kernel resources to prevent system or workload failures due to bottlenecks. One such example is a common problem seen on Linux systems running HANA where Soft CPU Lockup can occur due to Directory entry unused cache (dentunusd, as monitored by 'sar -v') growing very large to possibly billions. When the system runs low on memory available, it will trigger a reclamation of the dentunusd cache using all available CPU threads, thus locking up the system and HANA can be unresponsive for many seconds and even minutes.
IT-Conductor can now monitor these resources and based on a threshold, trigger automatic reclamation via recovery action, so the system avoids lockup when the resource utilization gets too high.
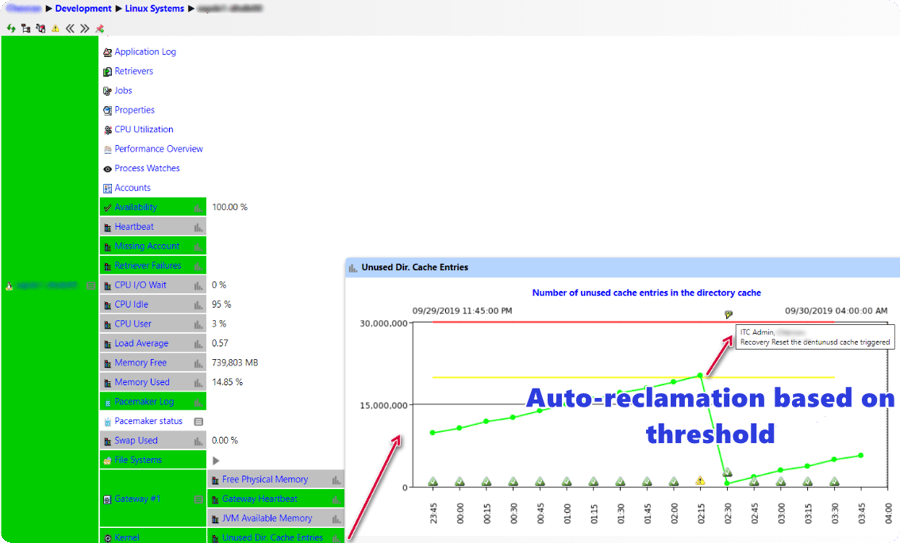
Figure 2: Linux Kernel Resource Management
3. HANA Memory Management
In the recent SAP TechEd 2019 Microsoft Azure announcement for a 12 TB VM, it's hard to believe that HANA can run out of memory and start column store unloads which impacts performance. We know that proactive performance management can help avoid these situations by tracking usage and where appropriate managing it within defined thresholds. In HANA many operations can affect the ballooning of resident memory usage, such as delta merge, a large volume of row store tables that by design loads on startup, long-running uncommitted transactions, etc. HANA has a very complex algorithm to manage the resident memory which sometimes can allow the memory management to grow for a long time without efficient reclamation. In these situations, when actually used memory by HANA services within the resident memory is low, it is often best to reclaim it via garbage collection without affecting long-running uncommitted transactions. IT-Conductor can use one or more memory KPIs, to trigger on-demand garbage collection and free up memory so system utilization can reflect actual resource usage, helping overall performance and right-size of VM instances to save cost.
4. HANA Automated Backup
IT-Conductor already can Automate the HANA Backup and Cleanup, now by monitoring the database backup age, we can use either script-based or SQL to backup the database when the age since the last successful backup reaches the desired threshold. This is ideal as we can set the threshold differently for weekdays versus weekends or any day of the week to back up more or less frequently to meet specific database RPO/RTO. This centralizes the monitoring and backup of databases and avoids the need for local cron schedules, and moves toward an enterprise solution.
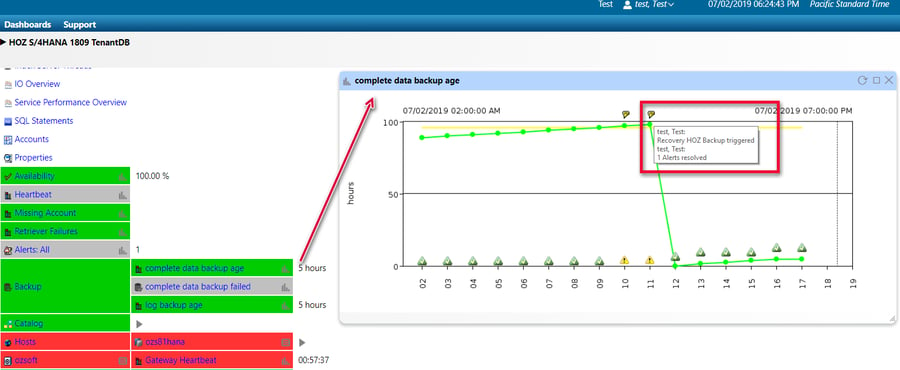
Figure 3: HANA Automated Backup
5. SAP qRFC Inbound and Outbound Queue Management
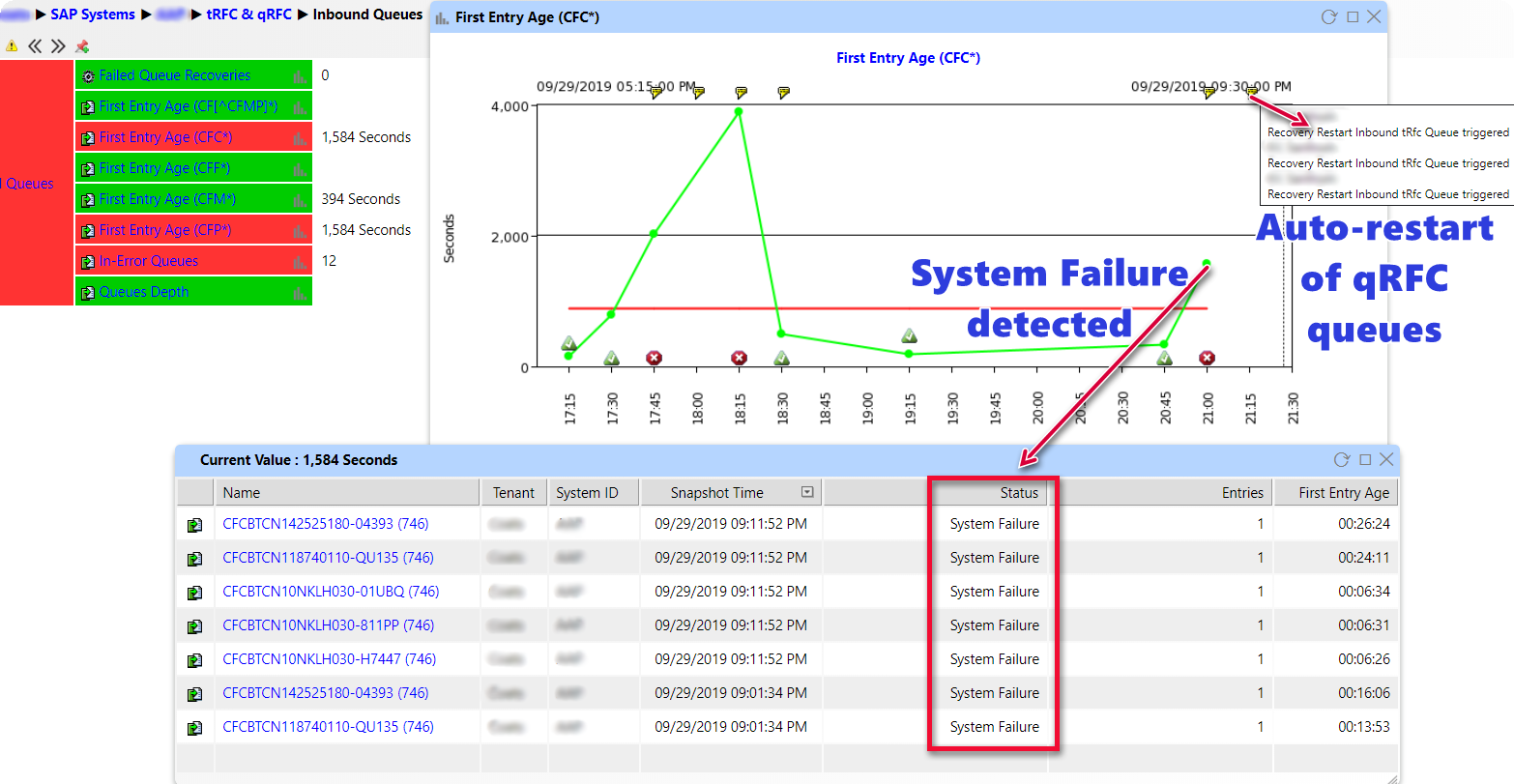
Most SAP customers have a complex multi-system landscape where data flows between various systems such as to/from ERP, CRM, SCM/APO. They require Core SAP Basis Monitoring to deal with one of the biggest pain points by managing the qRFC queues. Specifically, monitor and manage the inbound/outbound processing and ensure failed or stuck queues are recovered promptly to avoid business disruptions. Some of these systems may transact thousands of these queue objects daily as part of time-sensitive business processes, such as orders and supply chain jobs. IT-Conductor can now detect specific inbound and outbound queue conditions and automatically re-process individual queues that have errors or are stuck. Customers have found this automation to resolve more than 70% of issues that would have otherwise needed manual intervention.
Figure 4: SAP qRFC Inbound and Outbound Queue Management
6. Printer Queue Management
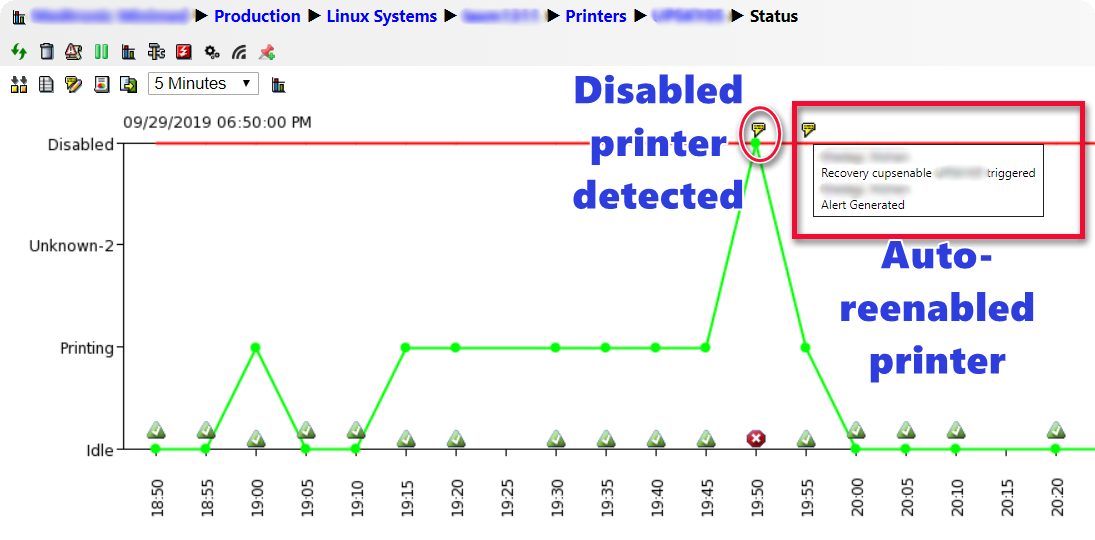
Although many customers have migrated to online printing from SAP to ADS (Adobe Document Services), there are still many use cases where physical printing from SAP is needed. Some examples involve the manufacturing floor where printouts are part of the product fulfillment process. When printing fails due to device errors, it can totally stop production. IT-Conductor already monitors the Printing and Spool Administration within SAP and the underlying spool subsystem, and now we have introduced remote printer restart which can resolve most of the print queue issues detected by IT-Conductor, except ink and paper (obviously).
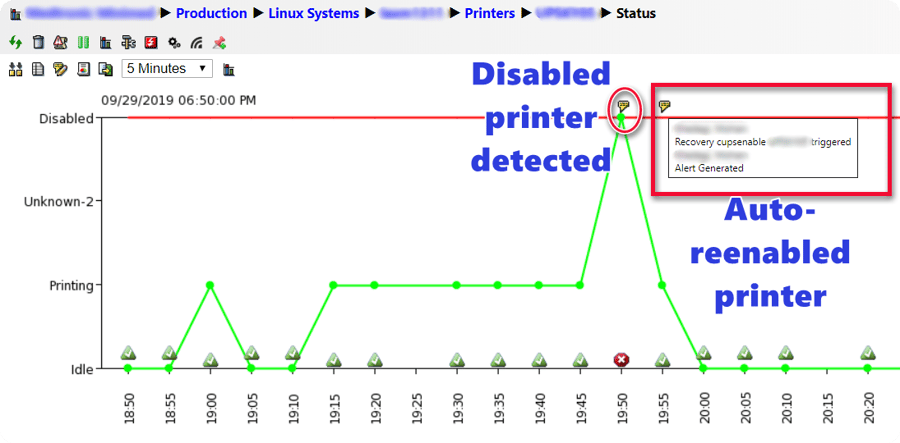
Figure 5: Printer Queue Management
7. SAP Jobs Management
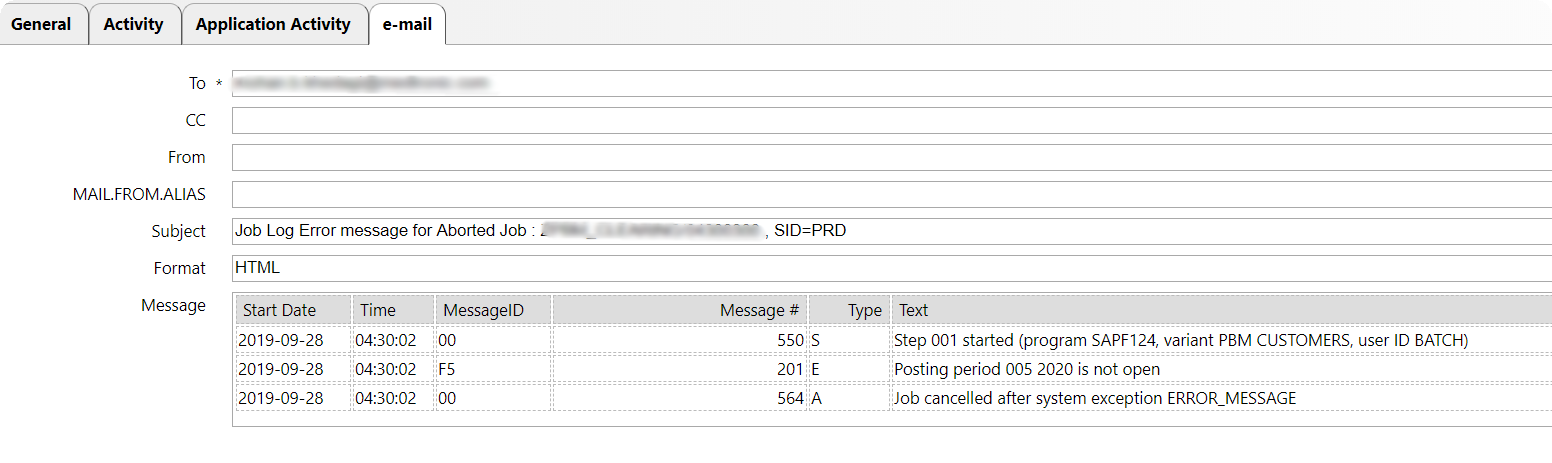
Most Jobs in SAP that fail eventually require a manual restart. When IT-Conductor monitors the SAP Background Processing environment Batch Jobs failures can now trigger specific jobs which should attempt a restart and/or send the job log as part of the notification. We understand not all jobs qualify for an auto-restart such as those that may have dependencies and manual data reconciliation, however, a large number of customer jobs if designed well should be safe to restart. In such a case, IT-Conductor recovery action can automatically copy the job to a new job and schedule it to run. The delivery of the job log that failed to the customer's inbox expedites the RCA and recovery.
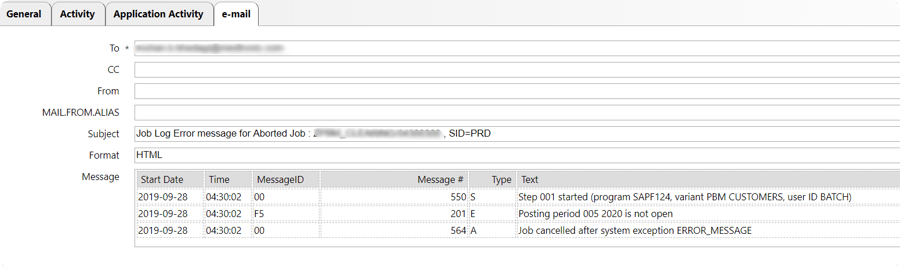
Figure 6: SAP Jobs Management
8. SAP System Performance Reporting
IT-Conductor provides dynamic dashboards and charts, but we also recognize that customers want periodic reporting sent to their inbox with an overview of their system's health. IT-Conductor supports report templates which can be easily scheduled and sent to a user or distribution list showing a performance overview of an entire SAP system and individual application servers, for the last 24 hours (configurable). Charts can include Dialog utilization, Background utilization, CPU utilization, Response time, Connections, Memory utilization, and users logged in.
9. Daily Recovery Reports
For compliance and audit logs, IT-Conductor does not alert customers on specific issues, run automatic recovery, and then on a configurable period such as daily, send a Recovery Report of the actions taken on the customer's behalf. These reports can show when, where, what, and how successful the recovery action was.
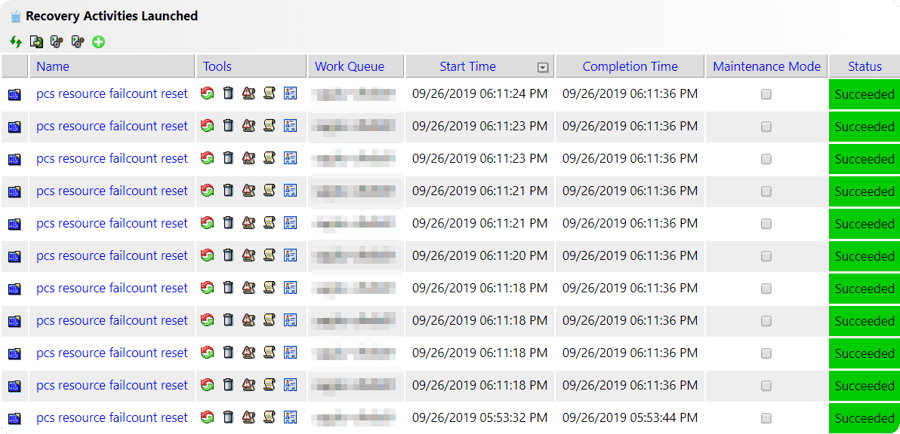
Figure 7: Daily Recovery Reports
10. Service Operations for SAP/DB/OS/VM stop/start/maintenance
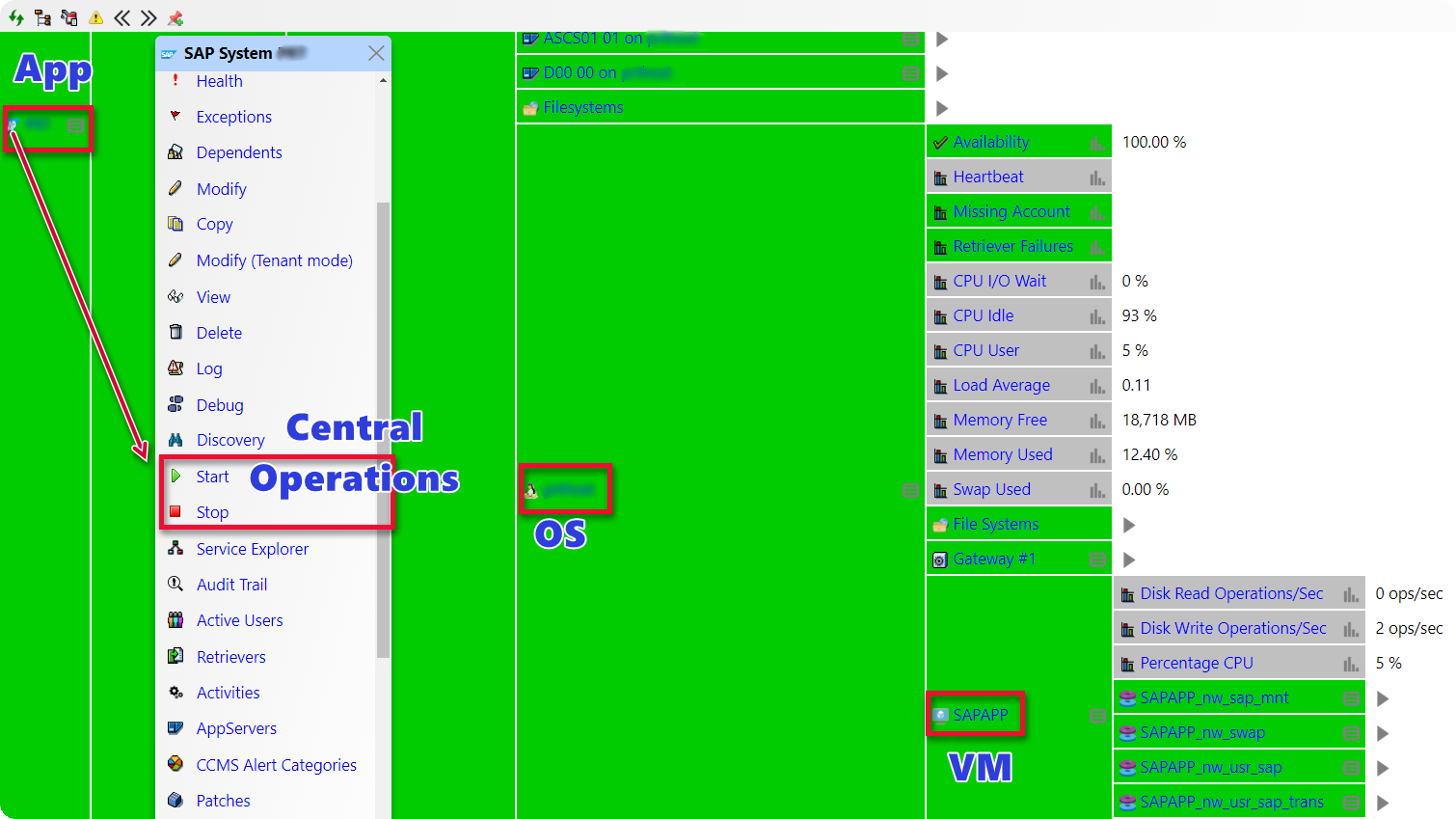
More than 2.5 years ago IT-Conductor introduced SAP on Azure monitoring and operations. Over the last year, IT-Conductor has Monitored and Managed the Largest SAP in the Azure environment and continued to innovate our SysDevOps capability, especially in operations automation. In a virtualized or physical environment, IT-Conductor can monitor and connect the relationships between services, applications, databases, hosts, and infrastructure components in order to facilitate service-oriented actions (e.g. stop, start). In a service context, IT-Conductor can propagate actions up or down the hierarchy to allow centralized control and scheduled operations for stopping, starting, and snoozing systems for maintenance or cost saving.
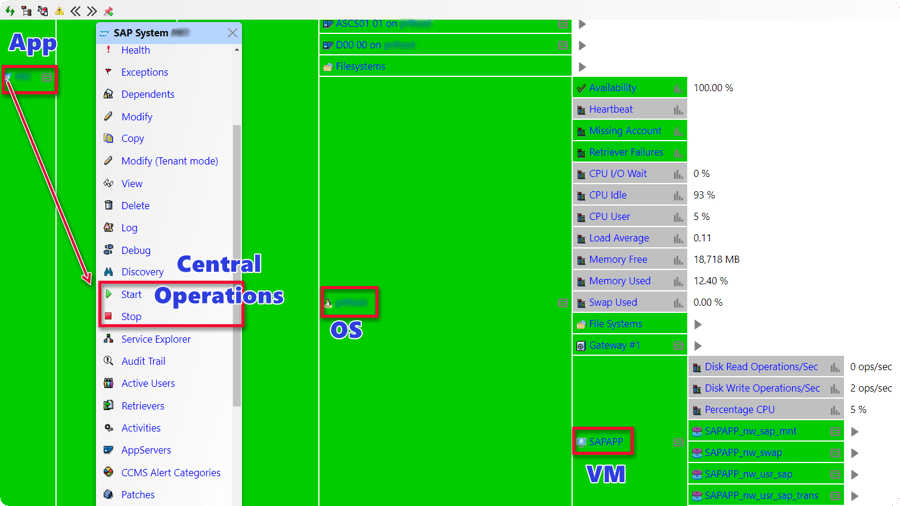
Figure 8: Service Operations for SAP/DB/OS/VM stop/start/maintenance
Go ahead and give these new features a try in your account, or if you would like to try IT-Conductor.